| Attribute | Description |
|---|---|
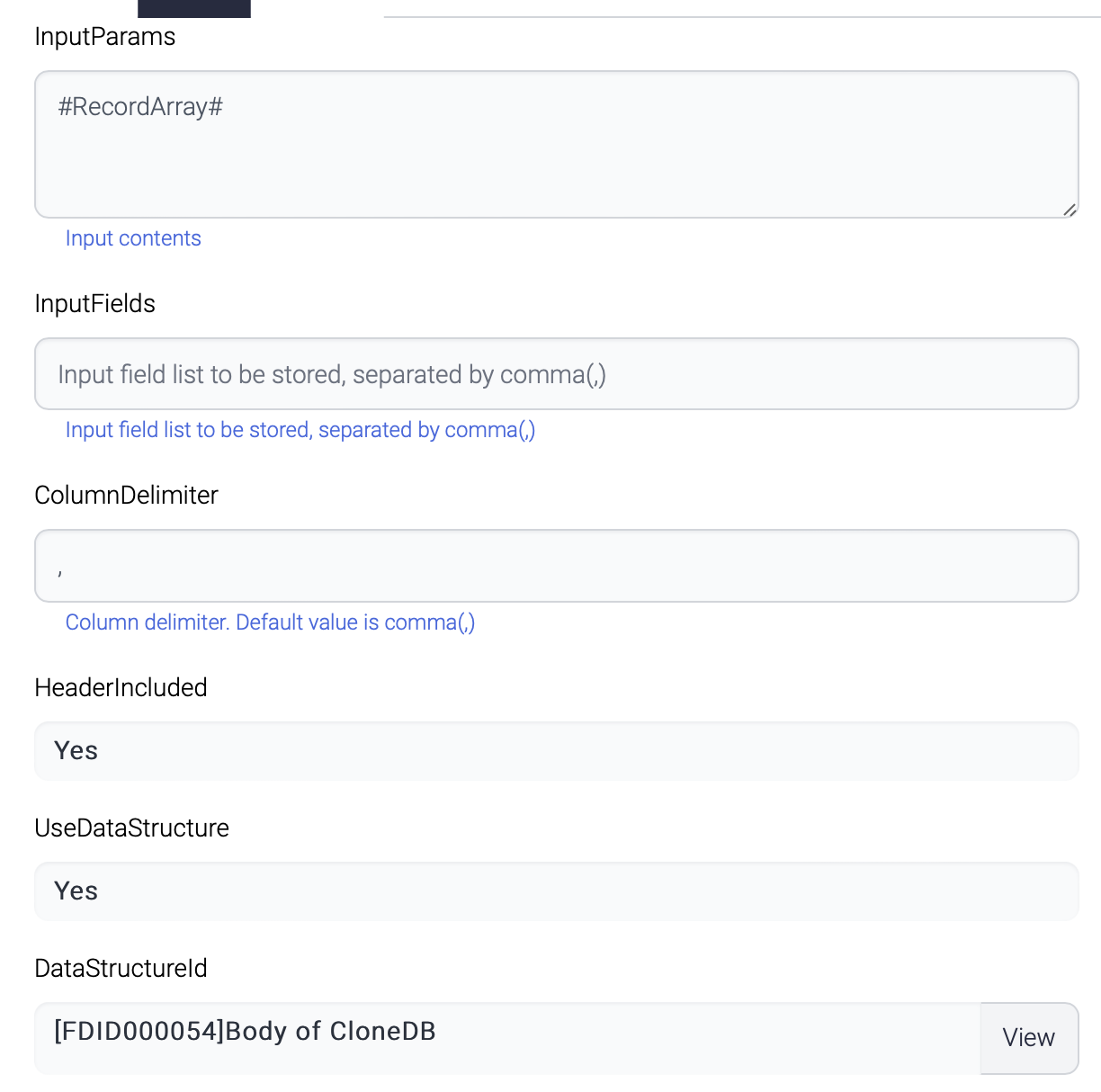
| Data Structure id | Data structure for the input data |
| Data Source | The source of input data File String Object |
| Input Name | The name of the input source File - File name with path String - Parameter name Object - Parameter name |
| Field Group | Field group of the output data |
| Use Carriage Return | Use carriage return(\r) and new line(\n) for windows file? |
| Storage Type | Storage type of extracted data. The default option is memory. But if the input data is high volume, OutOfMemory issue may be raised. File based array list is useful to avoid the memory issue.
|
| Attribute | Description |
|---|---|
| RecordArray | Extracted list |
| RecordCount | Record count |
| DataStructureId | Data structure id linked to the extracted data |
| Use In Mapping | Used in mapping component |
 ### FTP Input
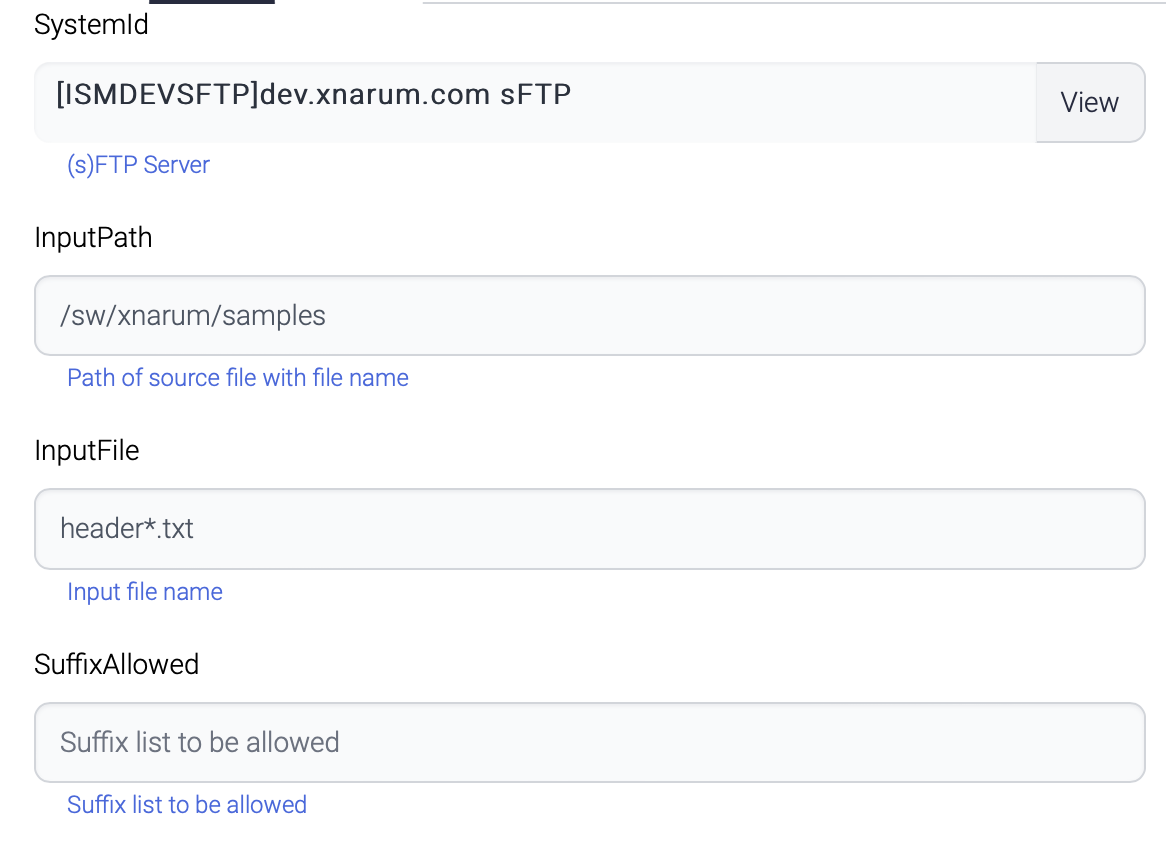
The FTP Input component gets header\*txt from the remote sFTP server and store in the local disk.
### FTP Input
The FTP Input component gets header\*txt from the remote sFTP server and store in the local disk.