| Name | Description |
 Publish Publish | Load selected flows to the cache. This operation asks to the instances to load flow information from database to cache. |
 Enable Enable | Enable the disabled flows. This change is published automatically. |
 Disable Disable | Disable the selected flows. This change is published automatically. |
 Pause Pause | Pause the selected flows. This change is published automatically.. Pause has effect only when the flow is invoked asynchronously. |
 Runtime Runtime | View runtime flow information. Each instance has its own cache in its own memory |
 New From Template New From Template | Create a new flow from the templates. The available templates are the followings:
|
| Export | Export the selected flows as json file |
| Import | Import flows from json file |
| Restore | Restore a flow from the backup |
| Execute(*) | Execute current flow manually. |
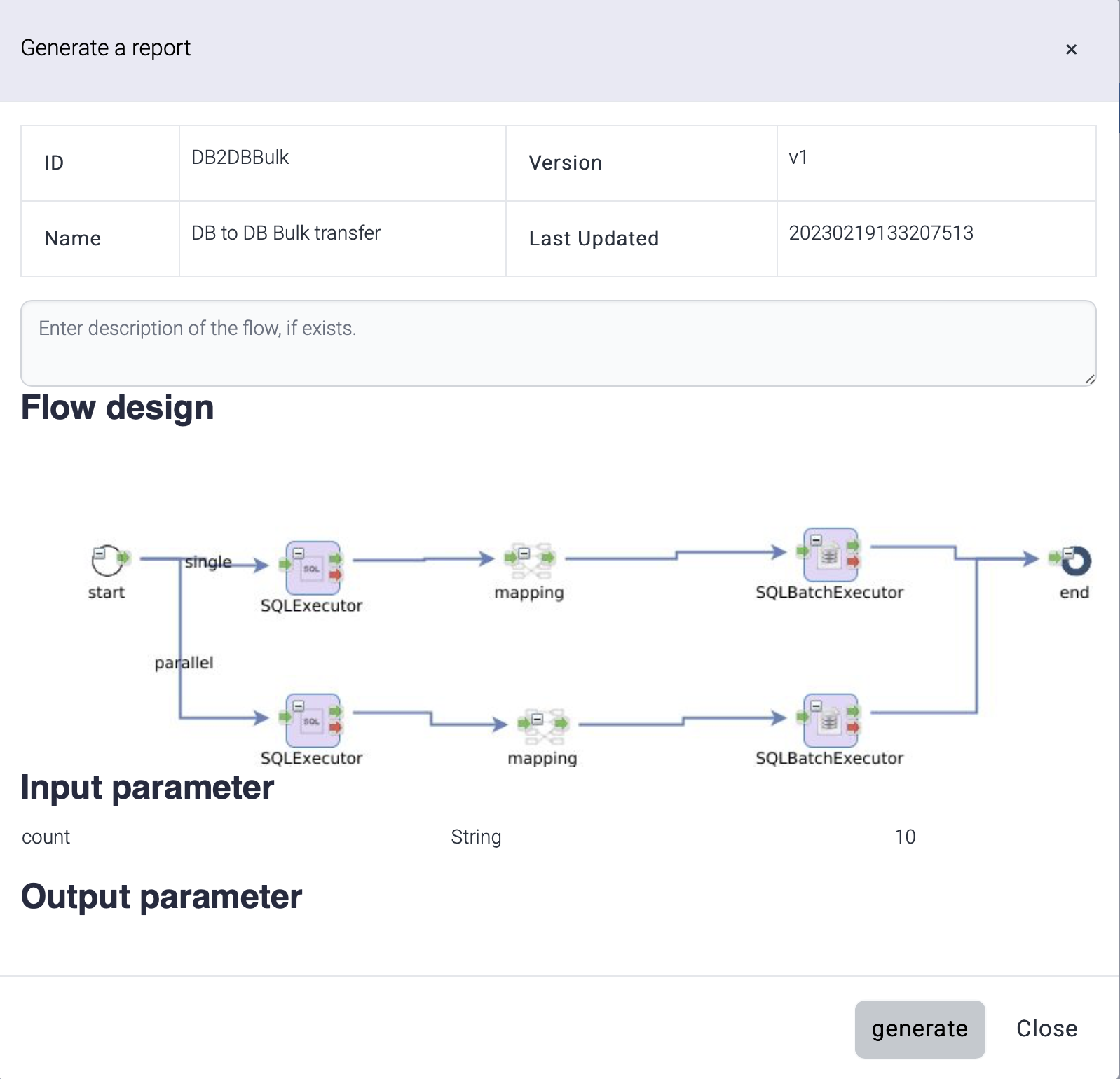
| Report(*) | Documentation about the flow is generated in word document(.docx). |
Export(*) | Export the flow design only. This function is used to copy flow design to another flow. |
Import(*) | Import the flow design only. This function is used to copy flow design to another flow. |
| Name | Description |
| Flow ID | Flow ID |
| Flow Name | Name of the flow |
| Flow Version | Flow version. v1 is assigned if not specified |
| Group | Application group. Default is assigned if not chosen. If this flow is generated by a normal user, the group of that user is assigned. |
| Retry Count | Retry count. Max retry count is 100. |
| Notification | If checked, an email notification is sent when the flow failed. |
| Single Transaction | If checked, all the sql operations are committed once after all the steps are compete. This attribute can work when one database is used for entire flow. |

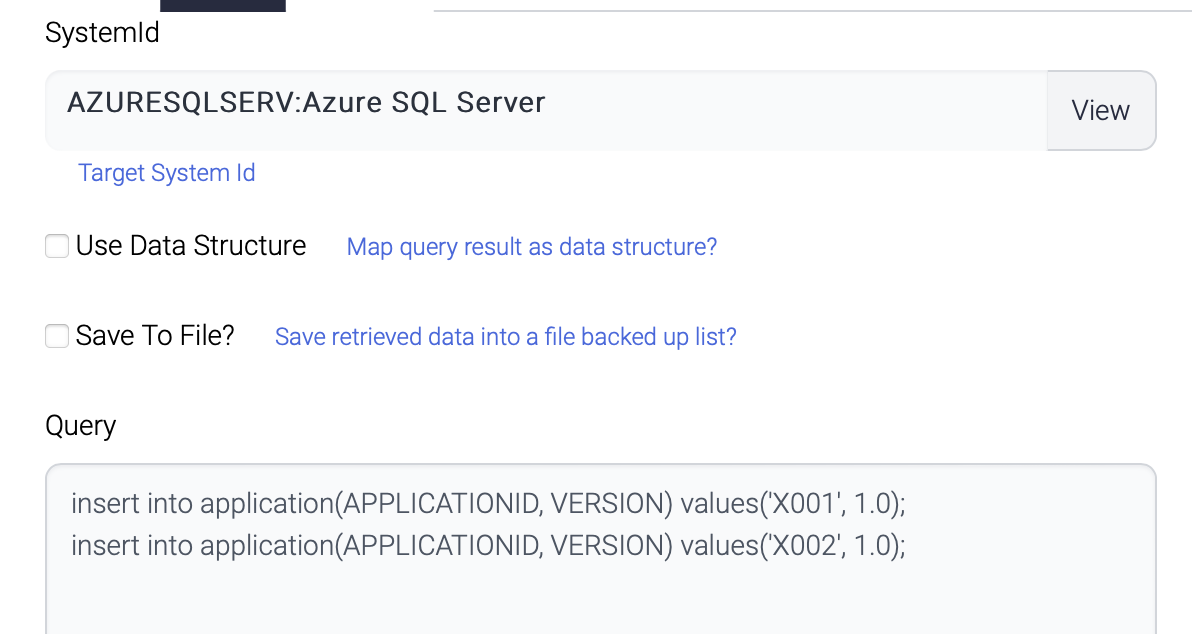
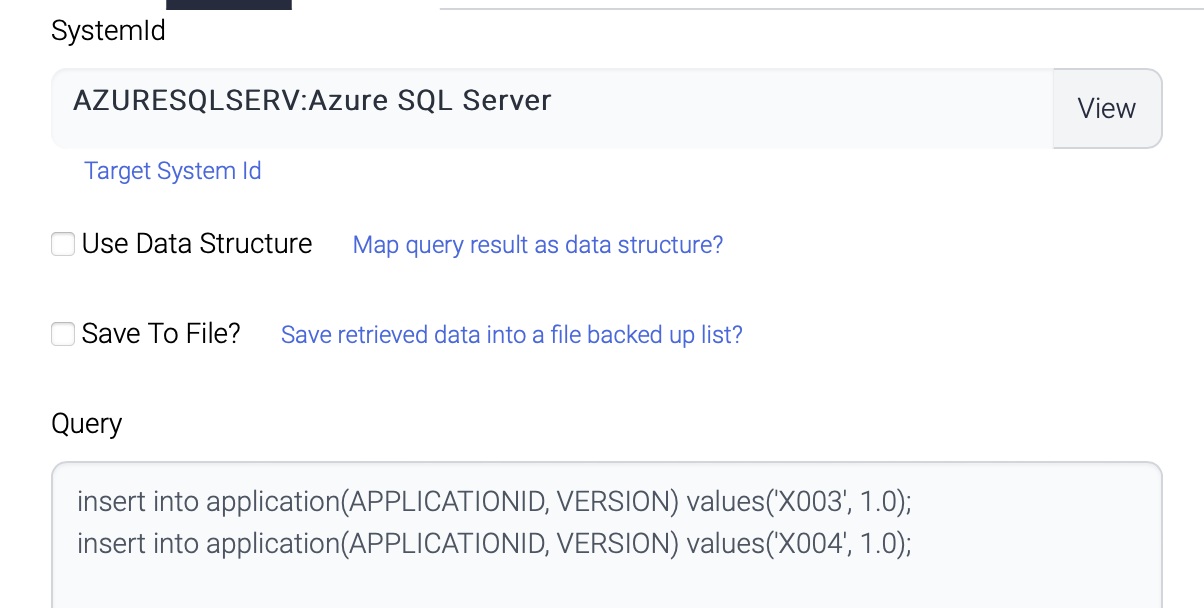

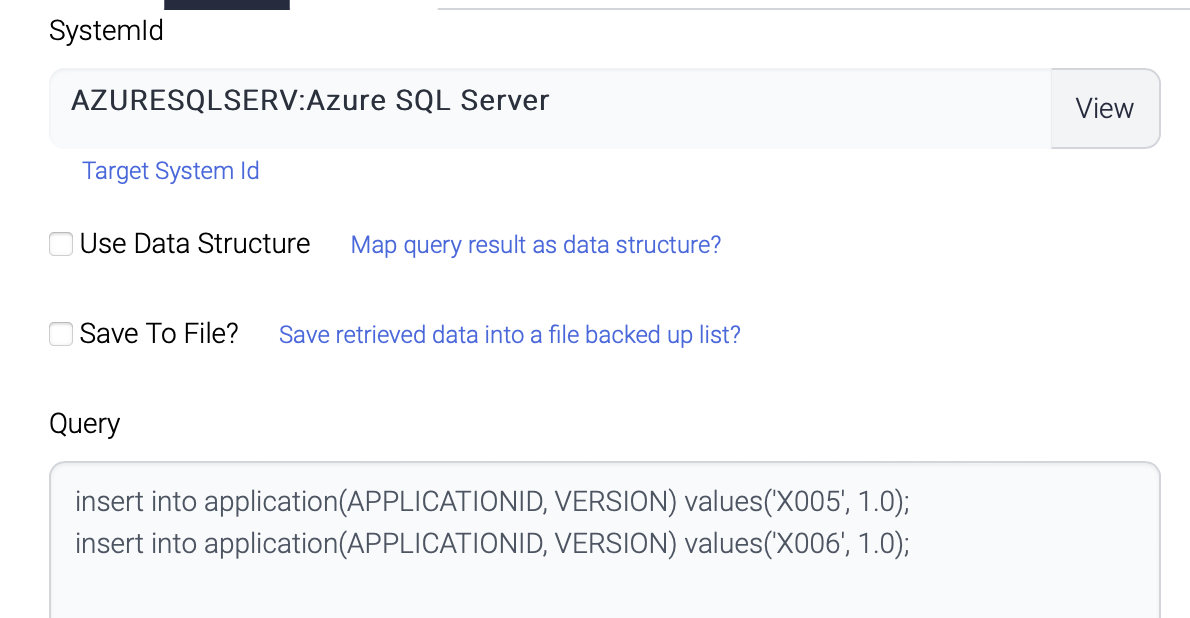
| Name | Description |
| Subject | Email subject |
| Sender | Sender of this email |
| Receivers | Recipients of the email. Recipients are delimited with comma(,). |
| Host | SMPT Server |
| Port | SMTP Port 25 - default SMTP Port 465 - default TLS Port |
| Use ssl | If checked, TLS(SSL) is used to connect to SMTP server. |
| Password | Password of the sender |
| Policy |
If the flow has retry count, email can be sent more than once. |
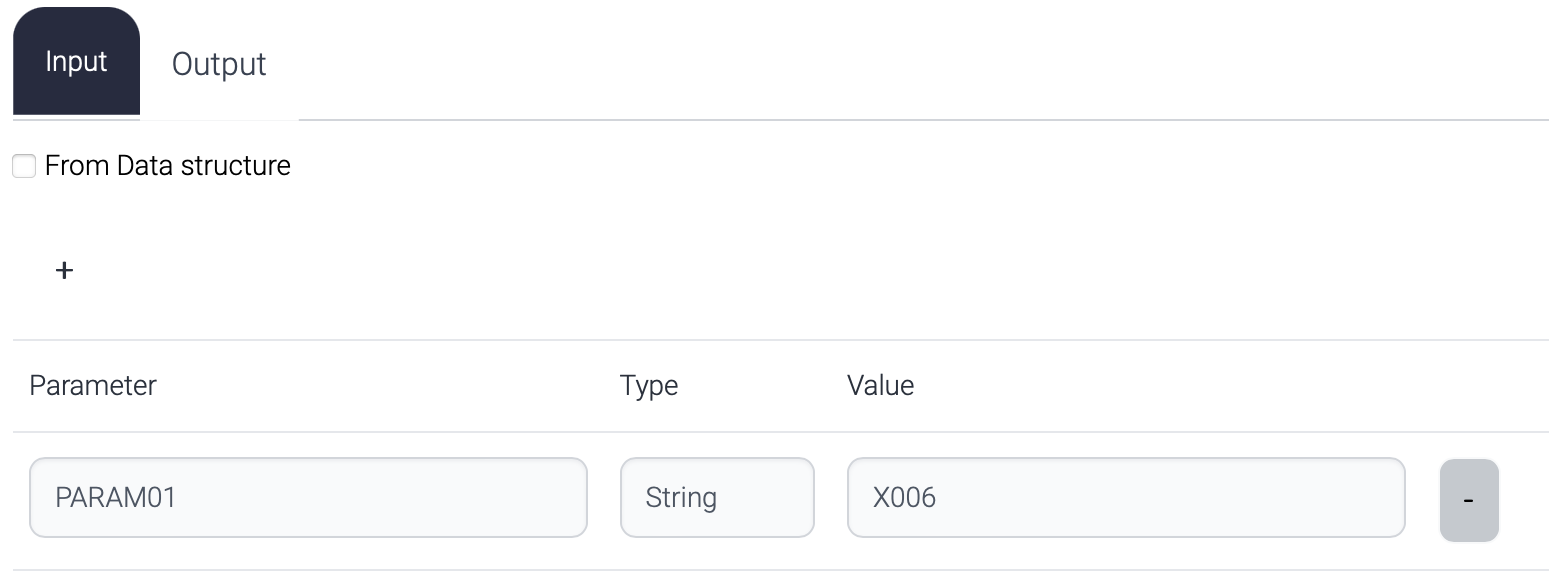

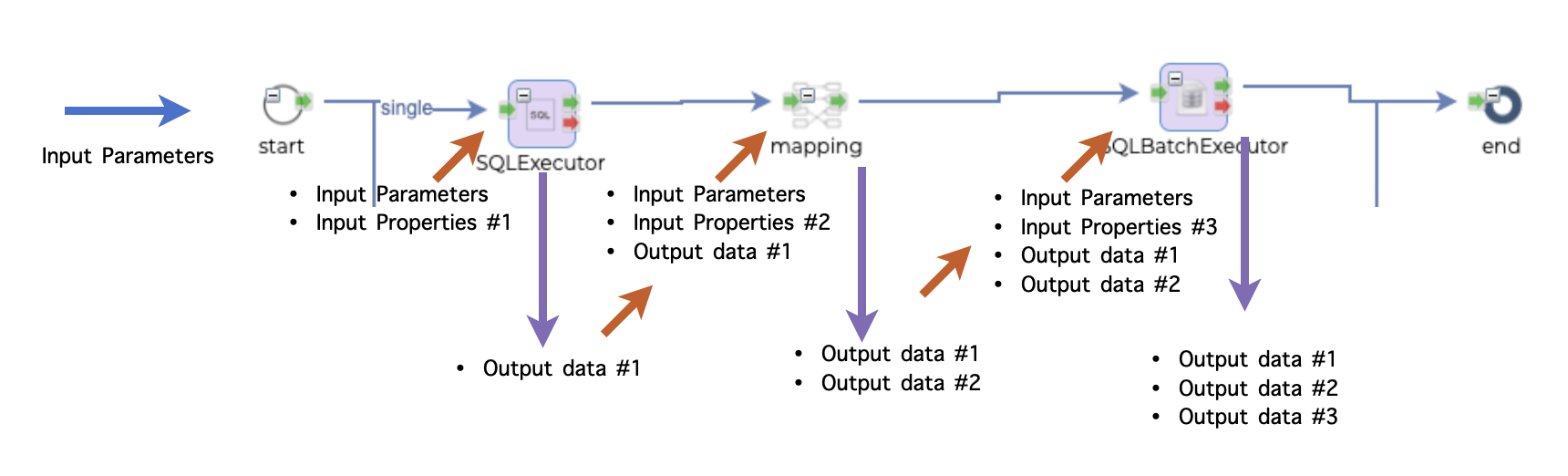
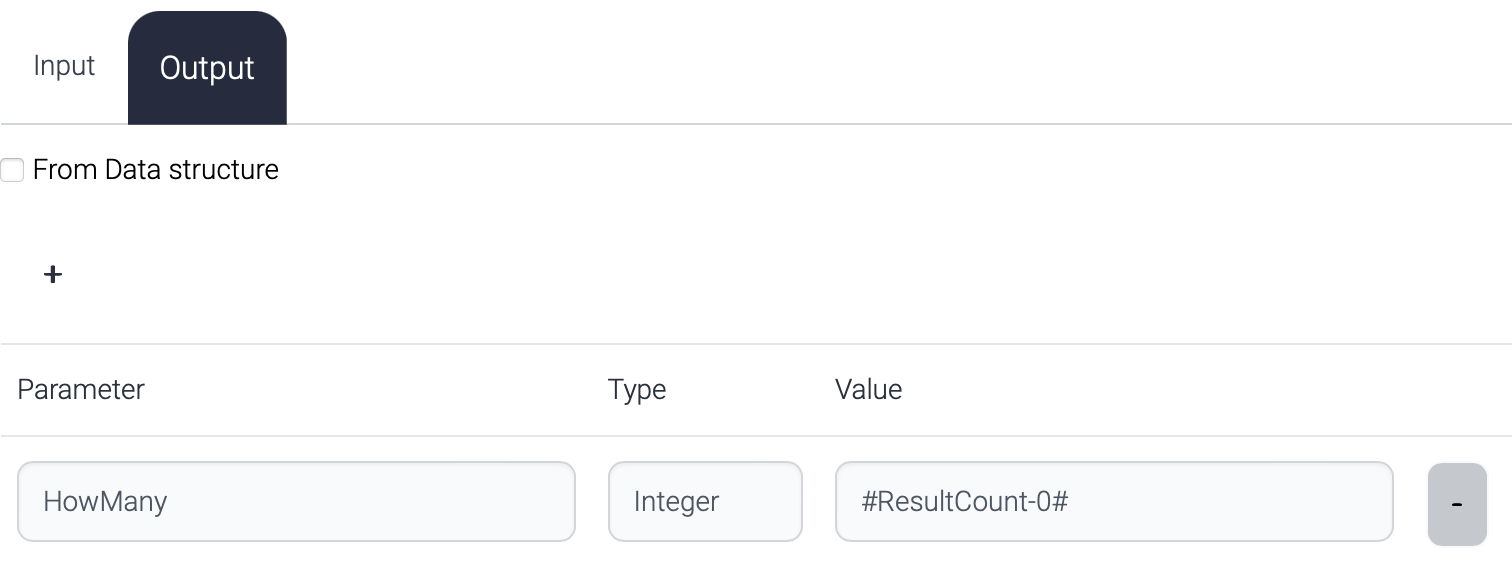
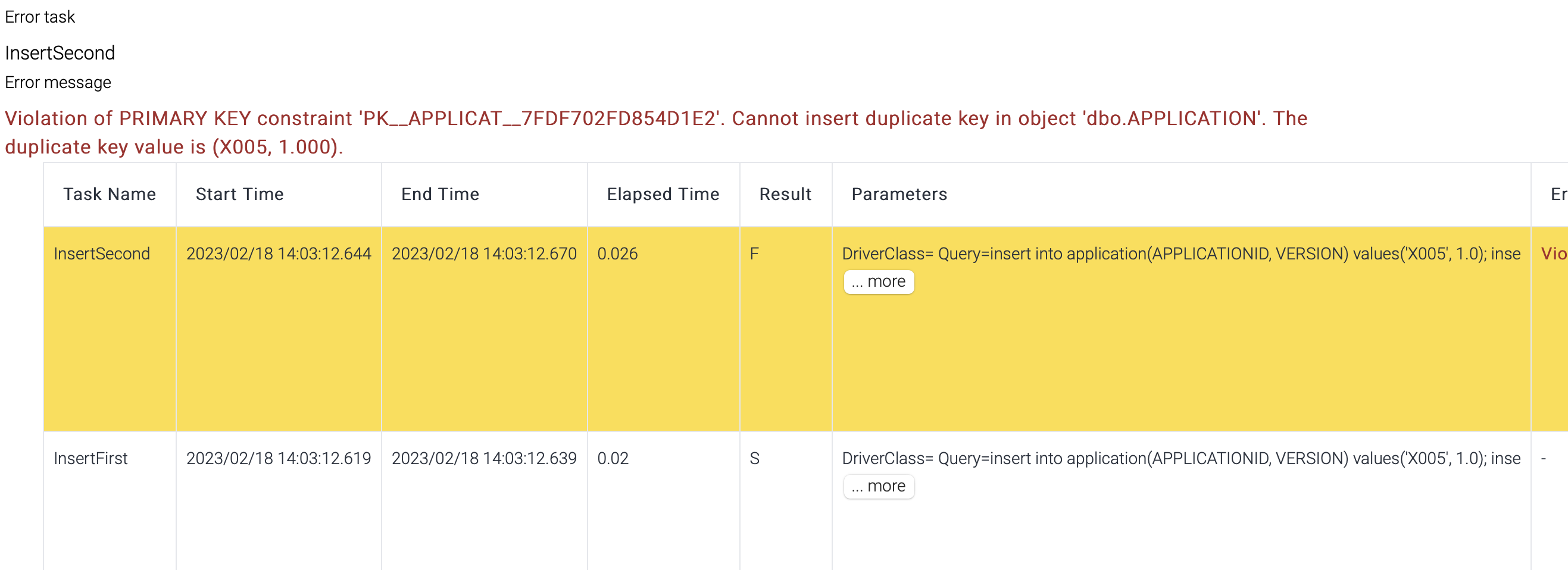
 .
To delete a node, click the node and click .
To copy a node, click the node and click
.
To delete a node, click the node and click .
To copy a node, click the node and click  and
and 
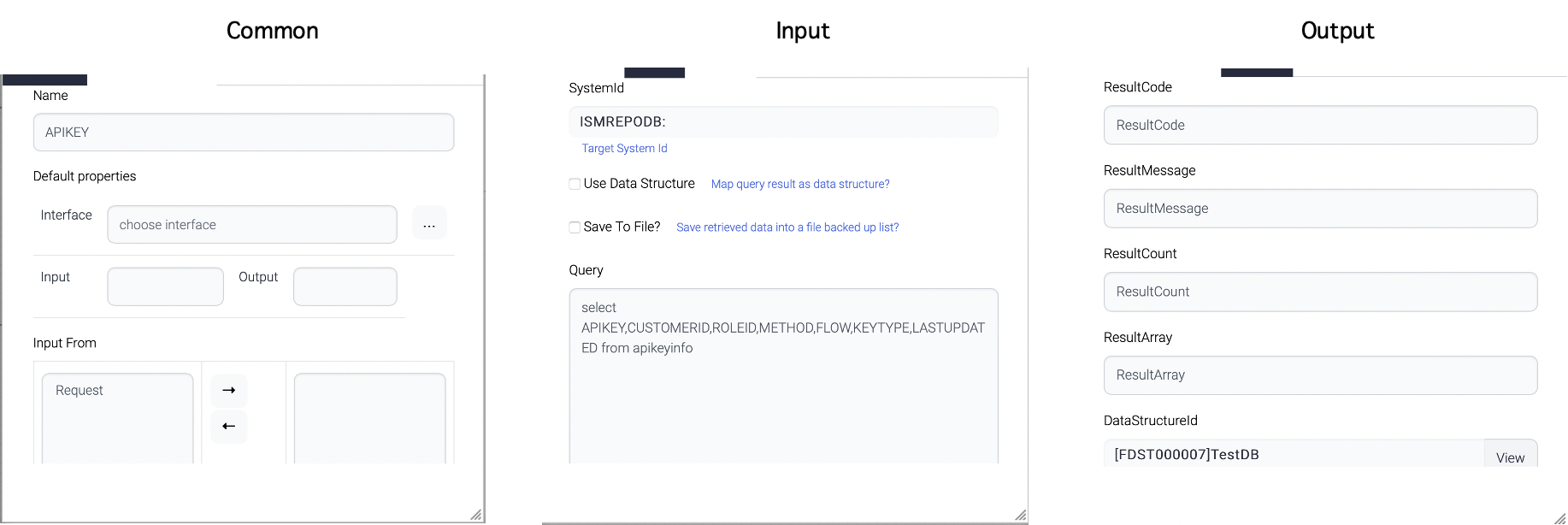


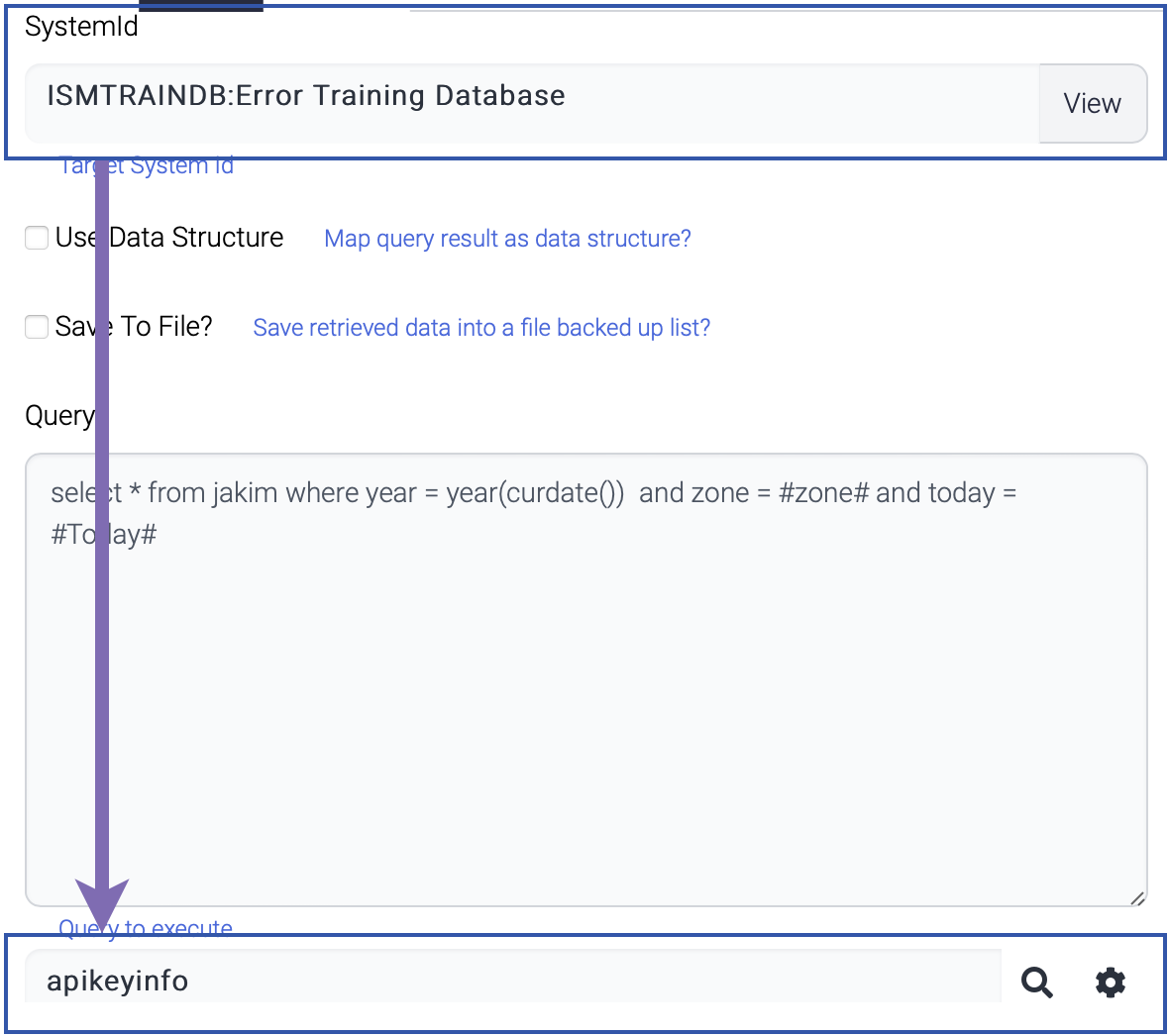
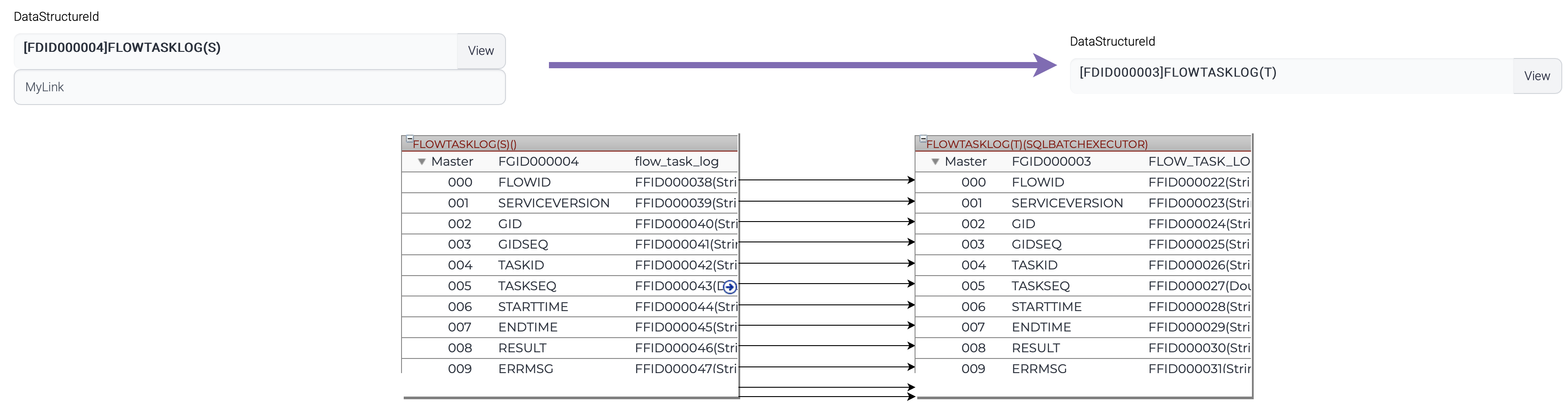

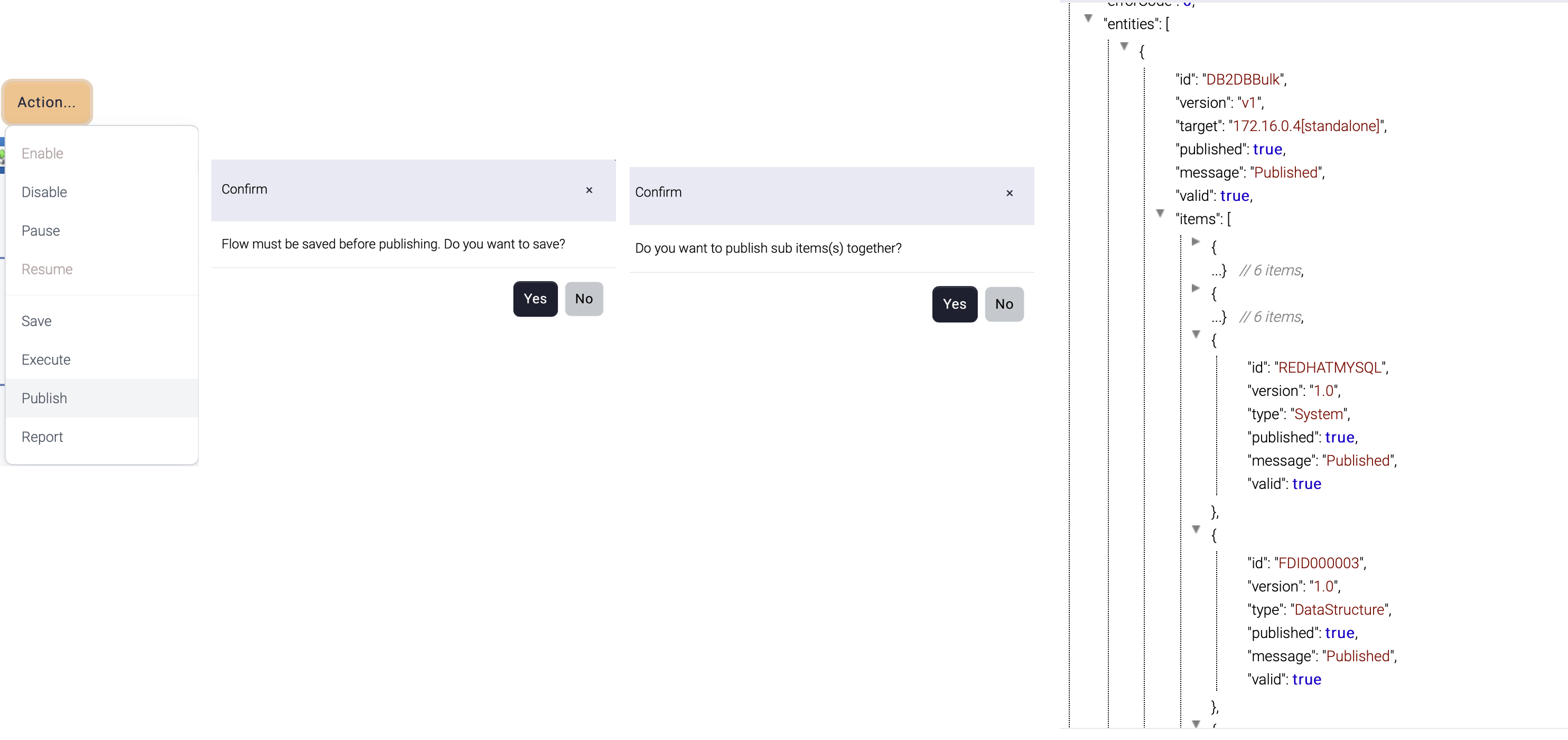
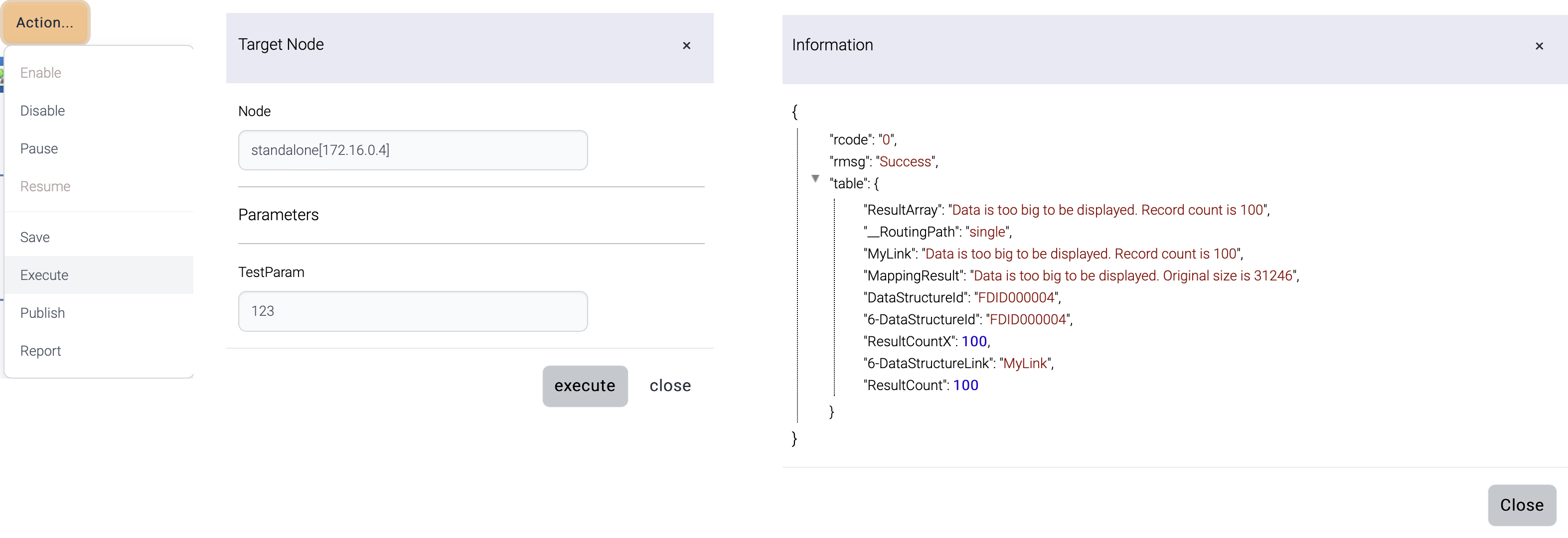
| Name | Description |
| rcode | Result code 0 = success 9 = error |
| rmsg | Error message |
| table | Response data |
 ) button then a popup window with xml contents is displayed. Copy with Ctrl+A, Ctrl+C and close.
!\[Graphical user interface, text, application
Description automatically generated]\() button then a popup window is displayed. Paste the copied xml data into the dialog. Close the window then the imported flow design is displayed.

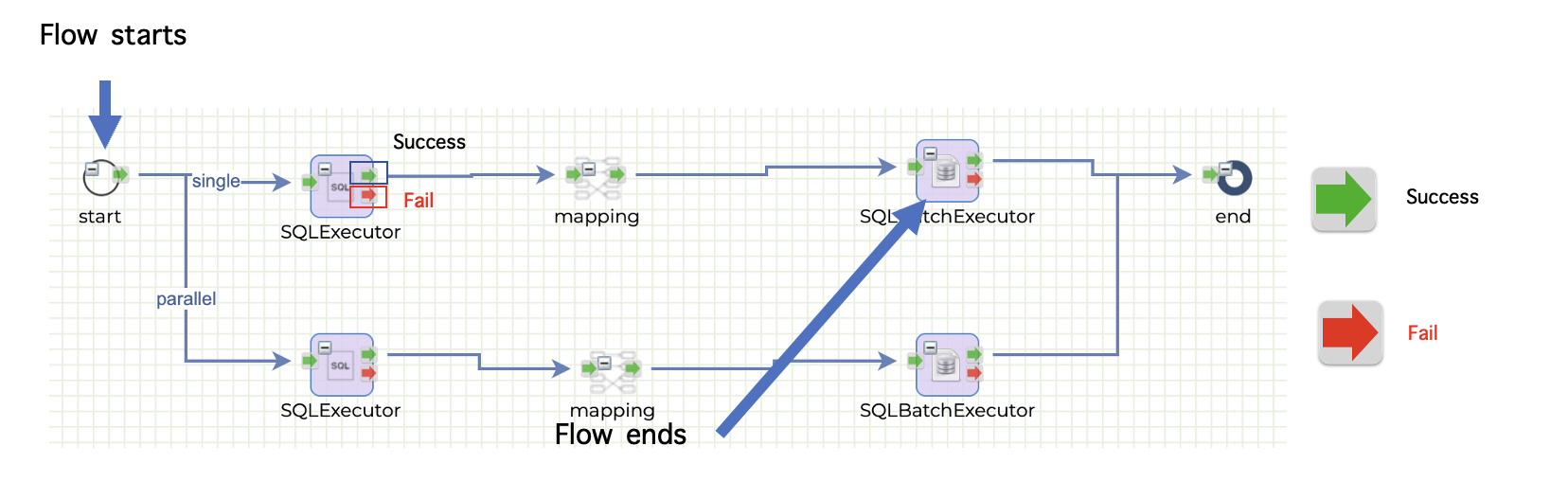
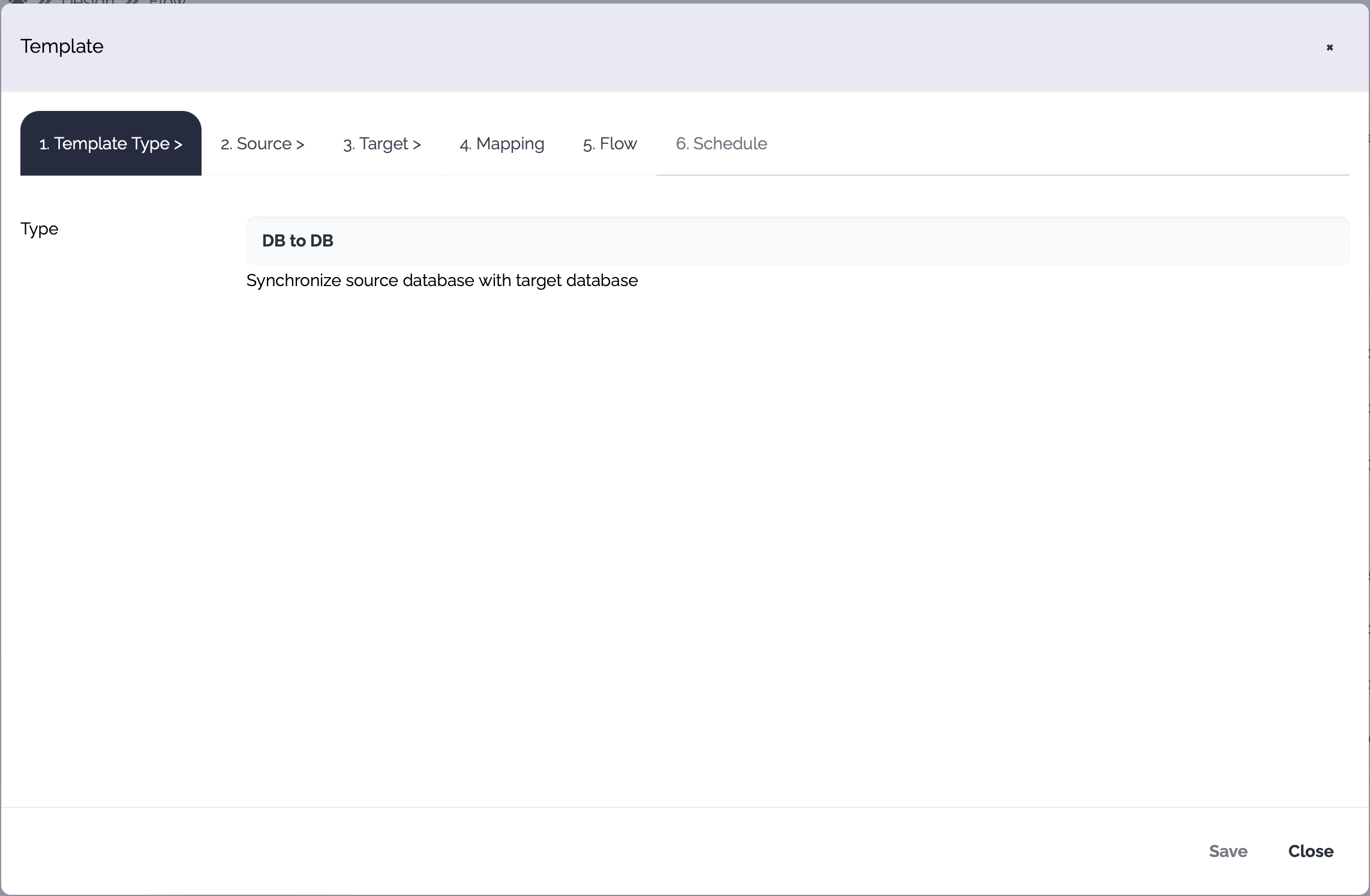
## **New flow from template**
A flow can be created from a template. The available templates are these.
* DB to DB
* DB to File
* File to DB
* File to File(With mapping)
* File to File(Get and Put) - The file is stored in the local disk before sending to the target server
* File to File(Transfer) - No local disk is used to store a temporary file
When you click New from template button, a new popup is displayed.
) button then a popup window with xml contents is displayed. Copy with Ctrl+A, Ctrl+C and close.
!\[Graphical user interface, text, application
Description automatically generated]\() button then a popup window is displayed. Paste the copied xml data into the dialog. Close the window then the imported flow design is displayed.

## **New flow from template**
A flow can be created from a template. The available templates are these.
* DB to DB
* DB to File
* File to DB
* File to File(With mapping)
* File to File(Get and Put) - The file is stored in the local disk before sending to the target server
* File to File(Transfer) - No local disk is used to store a temporary file
When you click New from template button, a new popup is displayed.
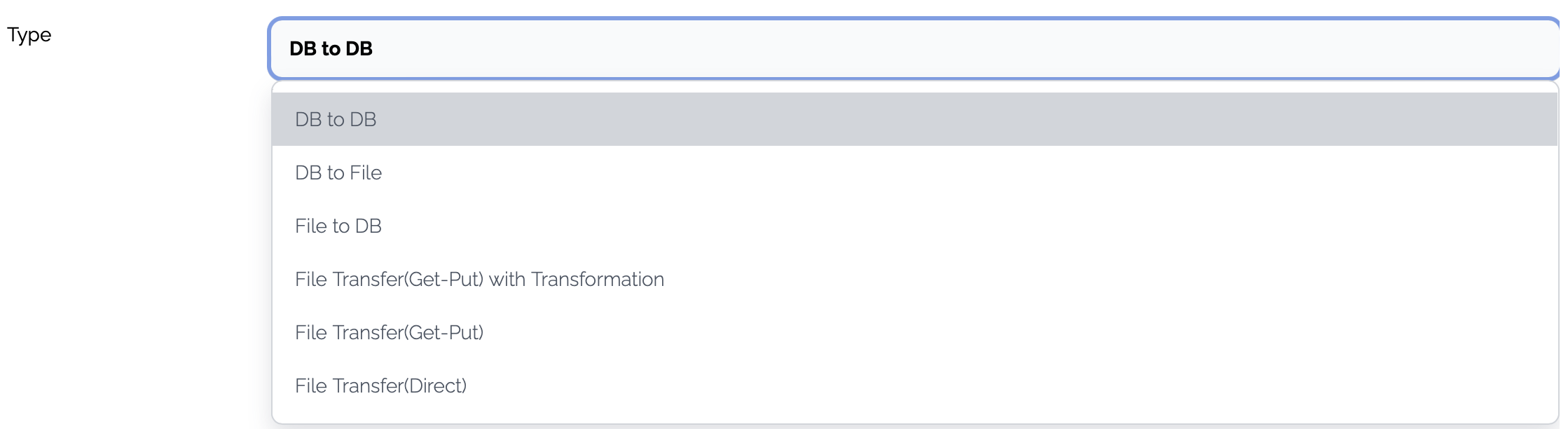
| Tab | Description |
|---|---|
| Template Type | Choose a template type |
| Source | The properties of the source system and operations are defined. A new system can be created through this flow generation and a new data structure can also be created. |
| Target | The properties of the target system and operations are defined. A new system can be created through this flow generation and a new data structure can also be created. |
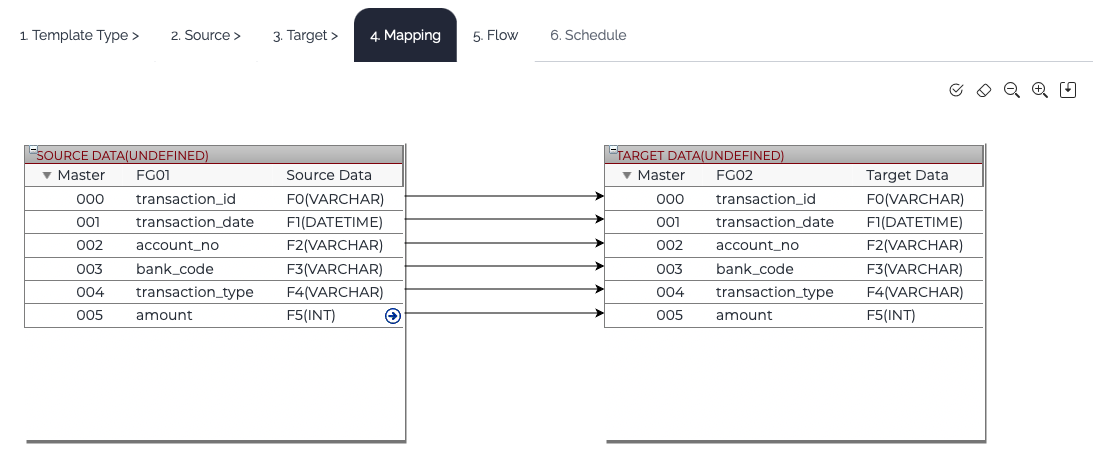
| Mapping | Mapping between the input and output can be generated. |
| Flow | Default properties of the flow are defined. |
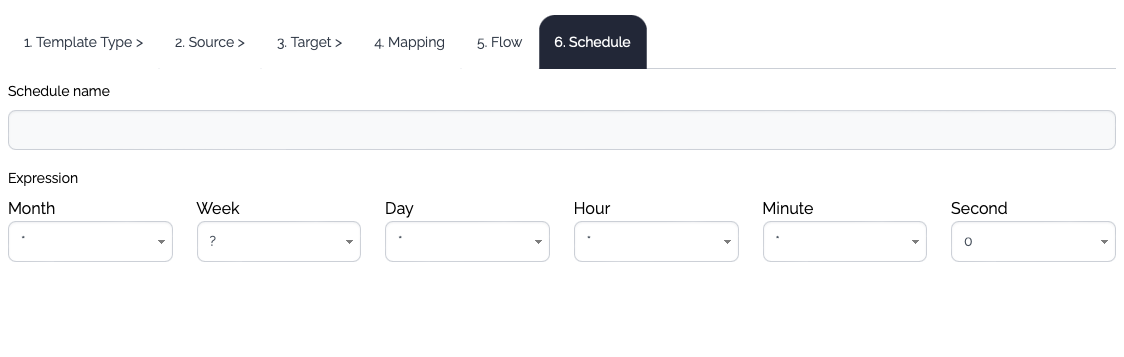
| Schedule | A schedule can be created but this schedule should be enabled manually later. |
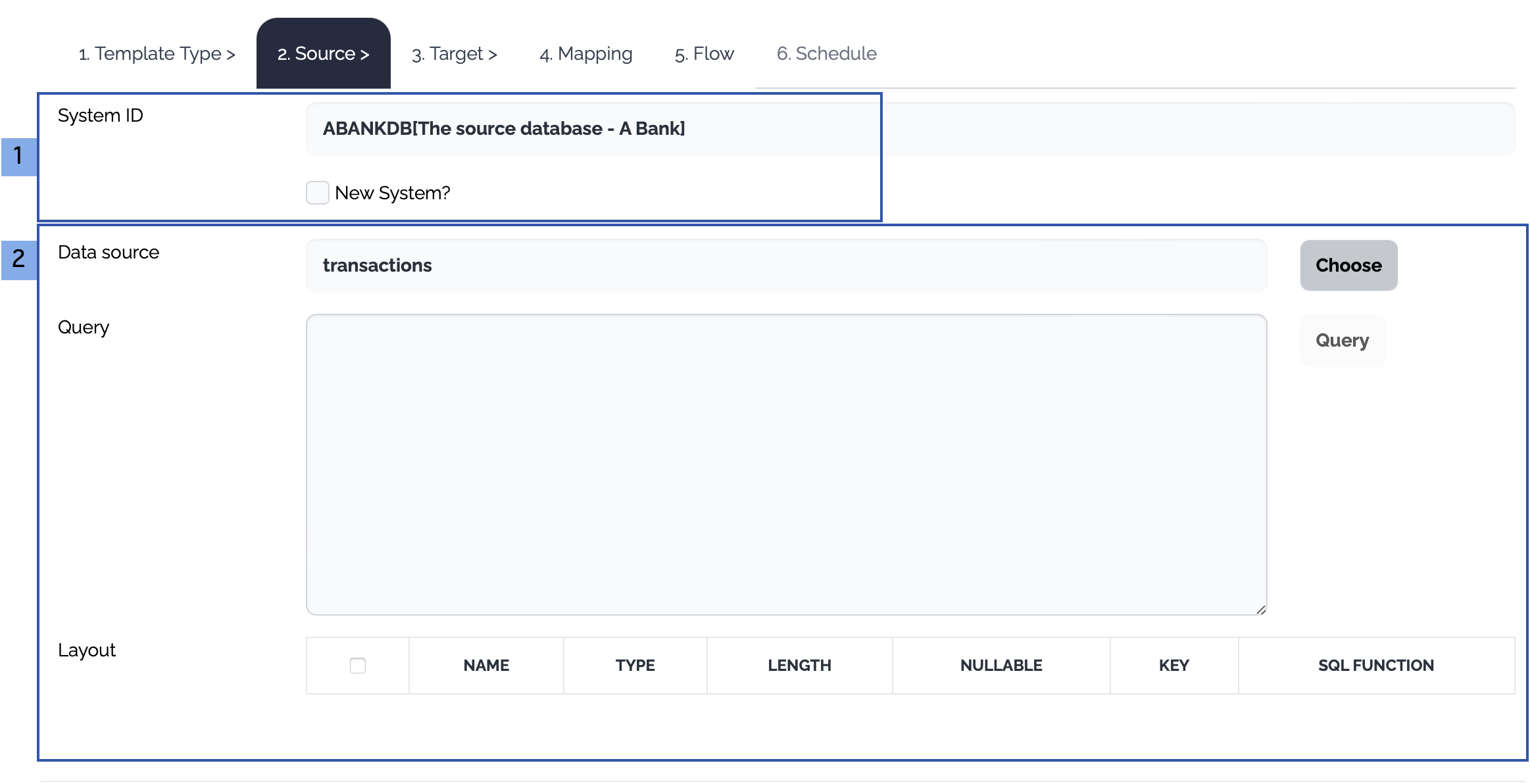
| Property | Type | Description |
|---|---|---|
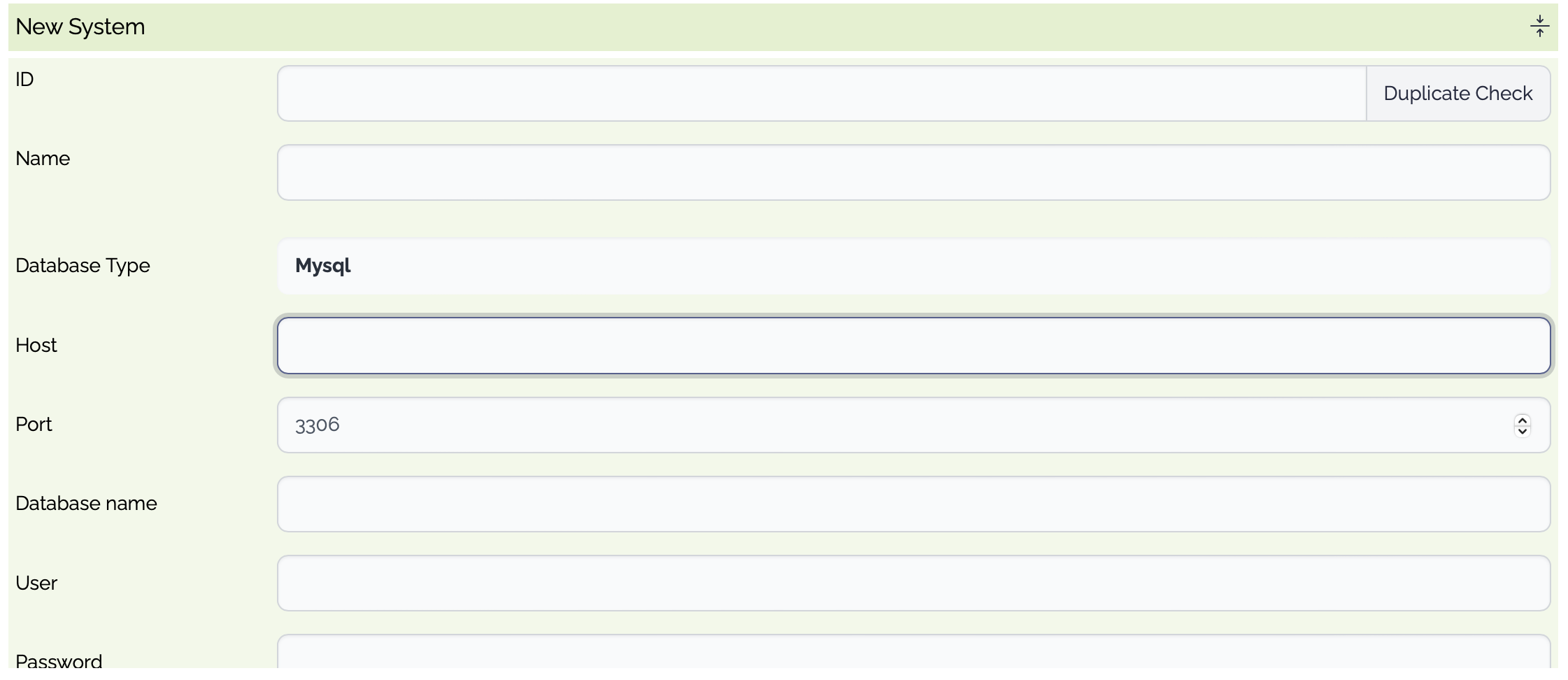
| ID | Optional | System ID. If empty, a random system id is generated. |
| Name | Optional | System Name |
| Database Type | Mandatory |
|
| Host | Mandatory | Database Host |
| Port | Mandatory | The listening port of the database |
| User | Mandatory | The user of the database |
| Password | Mandatory | The password of the user |
| Connection Pool Size | Optional | The maximum size of the connection pool |
| Validation Query | Optional | The query used to validate the connection |
| Connection String | Mandatory | The connection string used to connect to the database. If empty, a new connection string is generated automatically from the properties |
| Property | Type | Description |
|---|---|---|
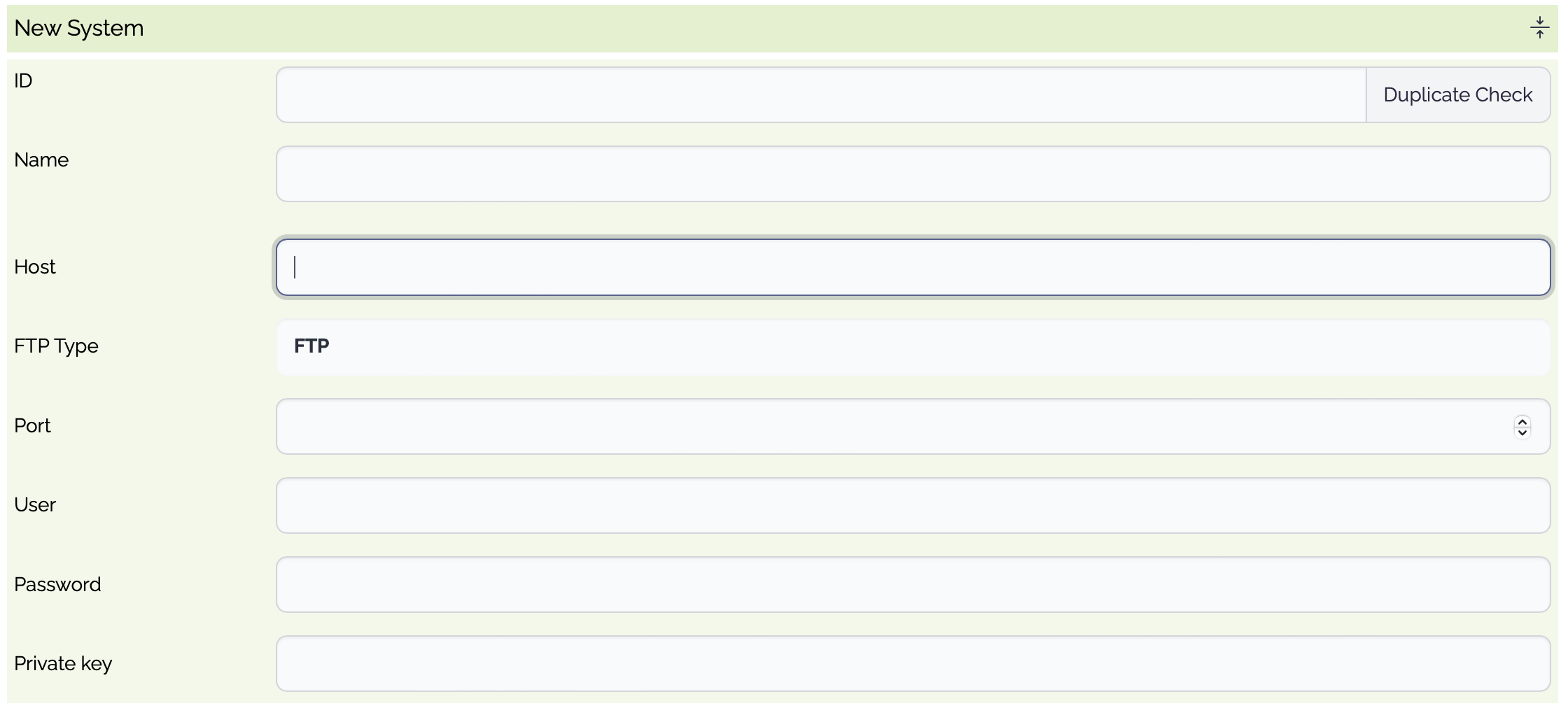
| ID | Optional | System ID. If empty, a random system id is generated. |
| Name | Optional | System Name |
| Type | Mandatory | File Transfer Type
|
| Host | Mandatory | File Host |
| Port | Mandatory | The listening port of the (s)FTP server |
| User | Mandatory | The user of the (s)FTP server |
| Password | Mandatory | The password of the user |
| Private Key | Optional | The private key of the user, if used |
| Passphrase | Optional | The passphrase to access the private key, if used |
| Property | Type | Description |
|---|---|---|
| Source File Path | Mandatory | The path of the source file - directory |
| Source File Name | Optional | The name of the source file. Only one file is processed for the template types which involves the mapping. |
| If Source File Not Found? | Mandatory | The action when the source file is not found.
|
| After Get Action | Mandatory | The action after the source file is collected.
|
| Backup Path | Optional | The name of the backup directory of the remote server. |
| Output File Path | Mandatory | The local path where the source file(s) are stored. |
| Need Data Structure | Optional | If the template types involve mapping, this property must be checked, and a new data structure should be created accordingly. |
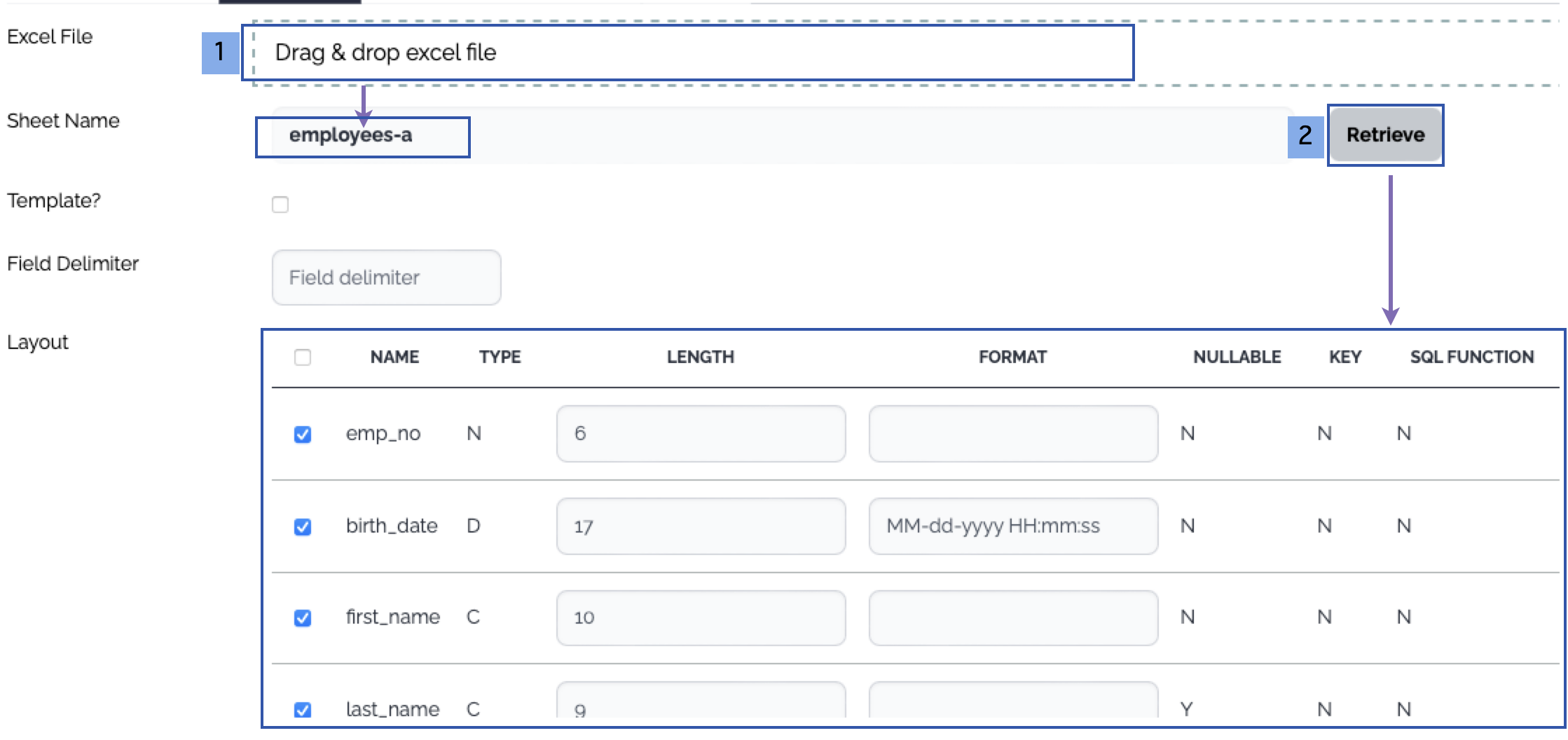
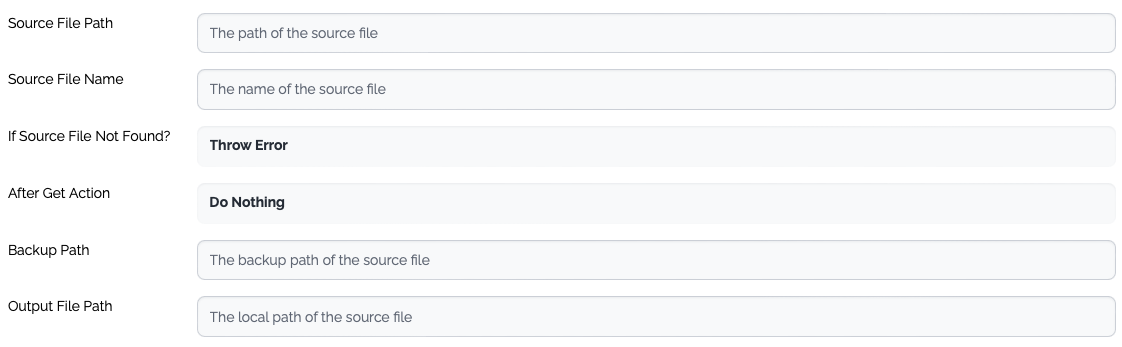
| Property | Type | Description |
|---|---|---|
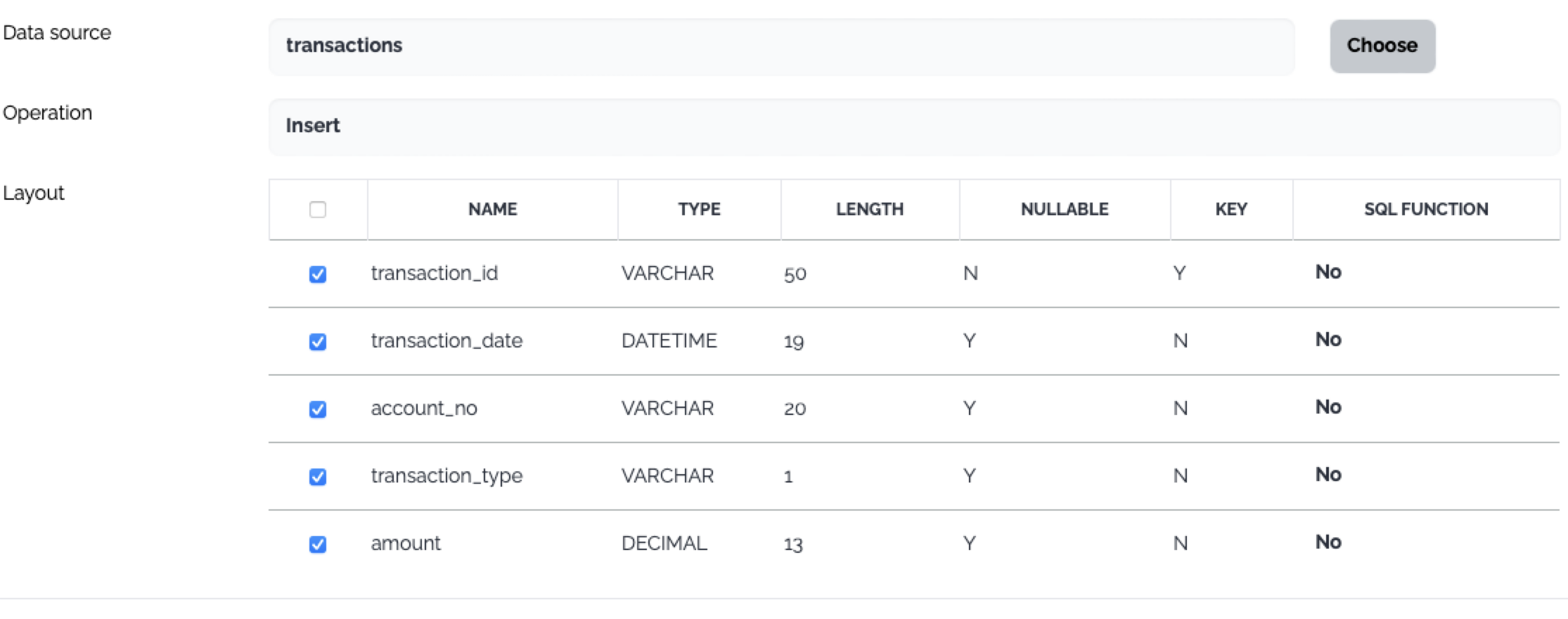
| File Path | Mandatory | The path of the target file - directory |
| File Name | Mandatory | The name of the target file. |
| Create Folders If Not Exist? | Mandatory |
|
| File Already Exist? | Mandatory |
|
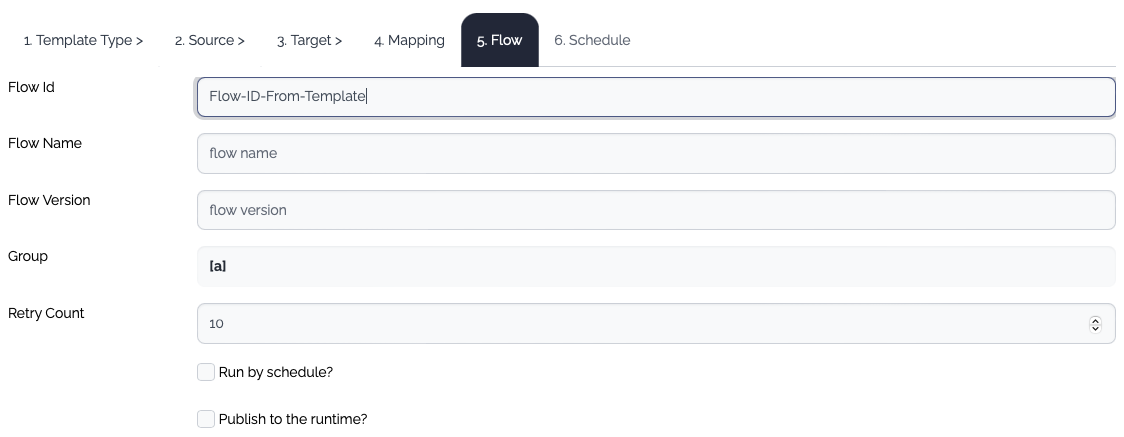
| Property | Type | Description |
|---|---|---|
| Flow ID | Mandatory | The id of the flow |
| Flow Name | Optional | The name of the flow |
| Flow Version | Optional | The version of the flow. If the version is empty, the default version name(v1) is assigned. |
| Group | Optional | The group of the flow |
| Retry Count | Optional | The retry count of the flow. The default value is 10. |
| Run by schedule? | Optional | If checked, The Schedule tab is enabled. |
| Publish to Rruntime? | Optional | If checked, all the items - data structure, system, flow - are published to the runtime. |