> For the complete documentation index, see [llms.txt](https://ism-docs.xnarum.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://ism-docs.xnarum.com/features.md).
# Features
## Use case of ISM
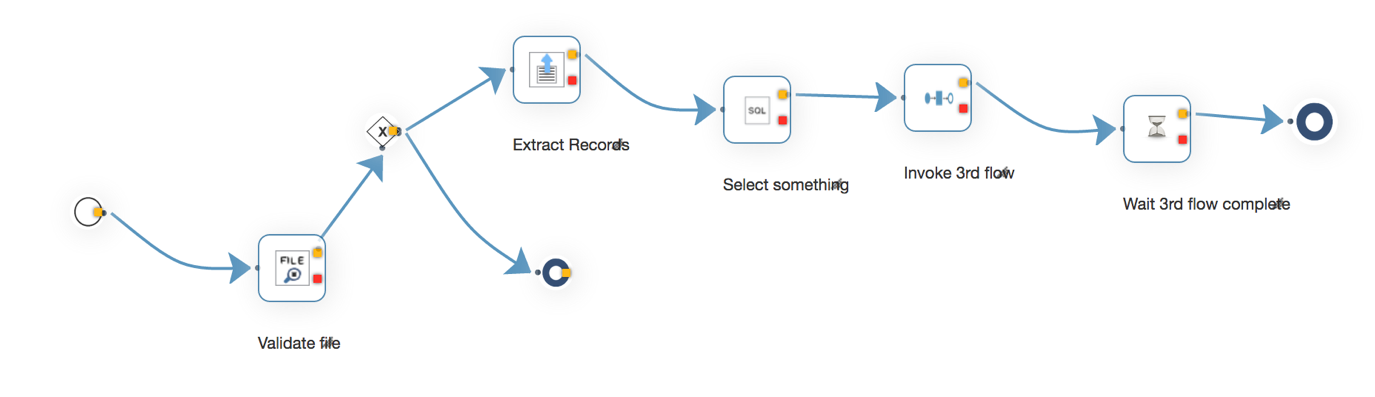
This picture shows a business flow designedvthrough Flow Manager.
While the captured picture may not exactly match the described scenario, it is similar enough to help illustrate the usage of ISM.
The scenario of this process is this.
Our clients submit information in fixed length format via text files to our (s)FTP server. To update and synchronize this information with our database, we collect and process these files. Prior to processing, we validate the file's structure and contents of each record to ensure accuracy. Once a record passes validation, we process it.
1. Validate input file
2. Route to the next step by some condition.
3. If the condition matches, extract the records from file.
4. Retrieve data from database.
5. Invoke another process, so called sub flow, with the records.
6. Wait until all the sub flows are complete.
Once the request for the flow arrives, the flow is executed from the start to the end.
## Retry
ISM has retry function for a flow execution. The scenario for retry is this.
When our clients send us a file, they expect a result from our operations. While the file is expected to have the correct structure and format, this cannot always be guaranteed. If the structure or format is incorrect, we generate an error file that provides a description of the failure cause. For example, 'File validation error: the 103rd record is incorrect'.
Upon receiving a valid file, we perform validation on each record. If a record passes validation, we execute and update it onto our database. In the event that a record fails validation, it will not be processed. It is necessary for us to notify our clients of the success and failure of each record. During record processing, we may encounter unexpected problems such as a timeout from the database or other systems, which are not related to the record itself but rather a system malfunction. When this occurs, our processing will fail. After the environment has been recovered, we must reprocess the affected records. However, the business logic for retry is not always straightforward. There may be updates that occurred during the initial processing, so we must skip those updates when reprocessing the record. The Flow Manager retry functionality considers this condition, allowing the Flow Designer to decide whether a task can be skipped or not. If 'skip' is chosen, the Flow Manager will reuse the result of that task from the last successful execution. The default option for retry is 'skip'.
## Sub flow Invocation
After validating a file's structure and contents, each record needs to be processed by executing the appropriate business logic and generating a result. This process involves picking up a record, executing the logic, and generating the result repeatedly. While this operation can be done in order by a single thread, the number of records in a file is unpredictable, and processing them all can take hours. To avoid this risk, the Flow Manager provides a task called FlowTask. Flow designers can use this task to design a repeating operation in a different flow that is executed per record and invoked by the main flow. When a sub flow is invoked, there is an option for synchronous or asynchronous invocation. Synchronous invocation waits until the sub flow is complete, while asynchronous invocation does not. If the result of the entire sub flow executions is required, the WaitSubTask is used to check the result of the sub flow executions.
!\[A screenshot of a computer
Description automatically generated with medium confidence]\()
## Flow Execution
### Scheduler
In the previous scenario, files are transferred on a schedule, and the flow must also be executed on that same schedule. Flow Manager provides a scheduler that can be used to set up cron-style schedules for flow execution. The scheduler offers three types of schedule invocation, allowing for greater flexibility in managing the flow's execution.
* Flow - invokes a flow with predefined parameters.
* Flow Trigger - involves file(s). If a file or files exist(s) in the specified (s)FTP directory, the designated flow is invoked.
### Exposing flow
Or the files may need to be processed by the external request. Flow Manager provides 2 types of endpoints.
* Web service endpoint
* RESTful service endpoint
A flow can be exposed as a SOAP web service by web service generation utility or exposed as REST endpoint automatically by publishing.
## Task
A task represents business logic of a specific step within a business process. Task has three types of attributes.
* Common - common attribute for all the tasks
* Input - parameters of a task
* Output - result data of a task
Common attributes are used by flow controller to determine common parameters and execution. Retry option is one of the common attributes. And some tasks use common attribute to construct dynamic input attribute list.
Input attributes are used by the task. Input attributes depends on the task. If the task is about file read operation, the path of file will be the input.
Output attributes are used by next tasks which will use result of previous task as input, which means input attributes of a task can be parameterized.
If you want to pick up the first FLOWID from the input below,
!\[A picture containing table
Description automatically generated]\()
The syntax of the parameter definition either of these two. But these two cannot be used together in one attribute.
| #ResultArray\[0].FLOWID# |
| ------------------------- |
| ${ResultArray\[0].FLOWID} |
The meaning of the parameter is this.
Input value comes from the output attribute named ResultArray of one of previous tasks and ResultArray is an array or list. That array or list contains FLOWID property and the first FLOWID will be used as input.
Task is a pluggable component. A custom task can be added on the fly and custom task needs to be implemented using java annotation.
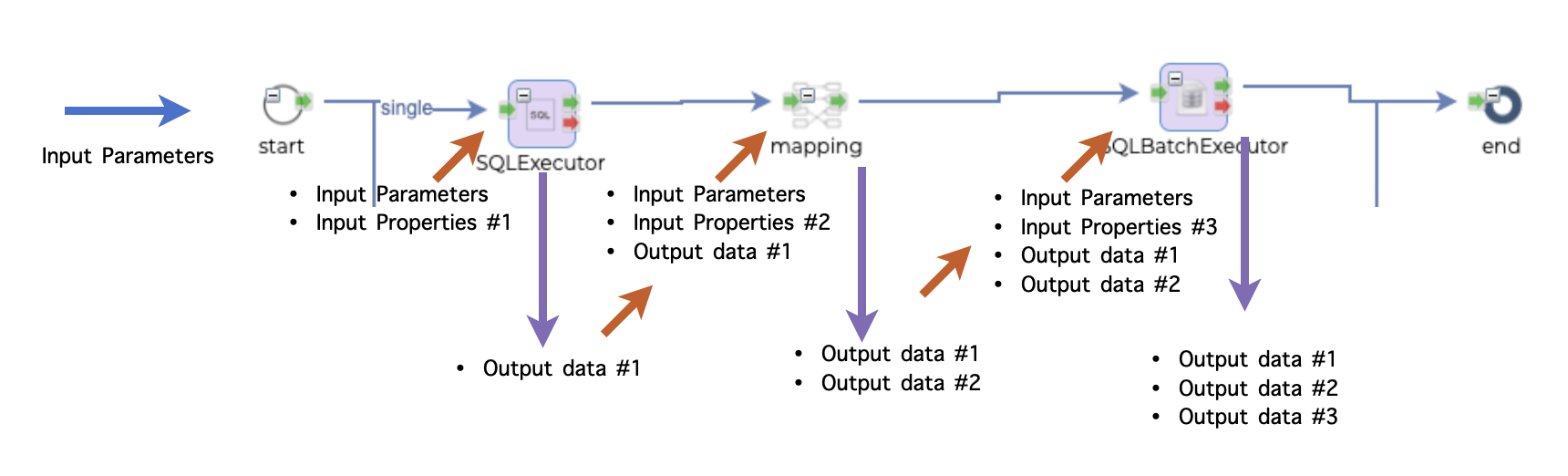
The flow of data or parameters inside flow is this.
Input parameters can come from 2 sources.
* From the client as request body of REST call or XML contents of the web service
* From the flow definition
Every output data of each step is passed to the next step as input data.
If an output name is duplicate, it is overwritten with the last one. In the picture above, the second component generates Output A, and this Output A is already generated by the first component. Output A of the first component is replaced with the second Output A and passed to the third component.
## Access control
Flow Manager provides finer access control than Swordfish. Swordfish provides only menu based access control. Access control of Flow Manager is about activities. And access control is about role not user. All the users with same role have same access privileges.
These are the access control list of ISM.
* Access - access the menu(page)
* List - list up the information.
* View - View detail information.
* View - View detail information.
* Edit - Modify an item.
* Delete - Delete item(s).
And if activity log flag is on, all the activities are logged.