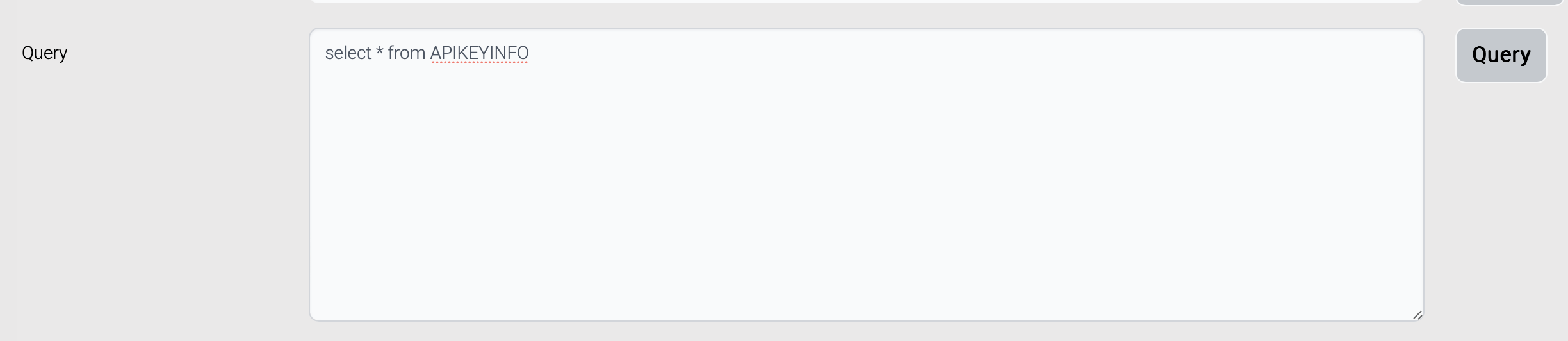
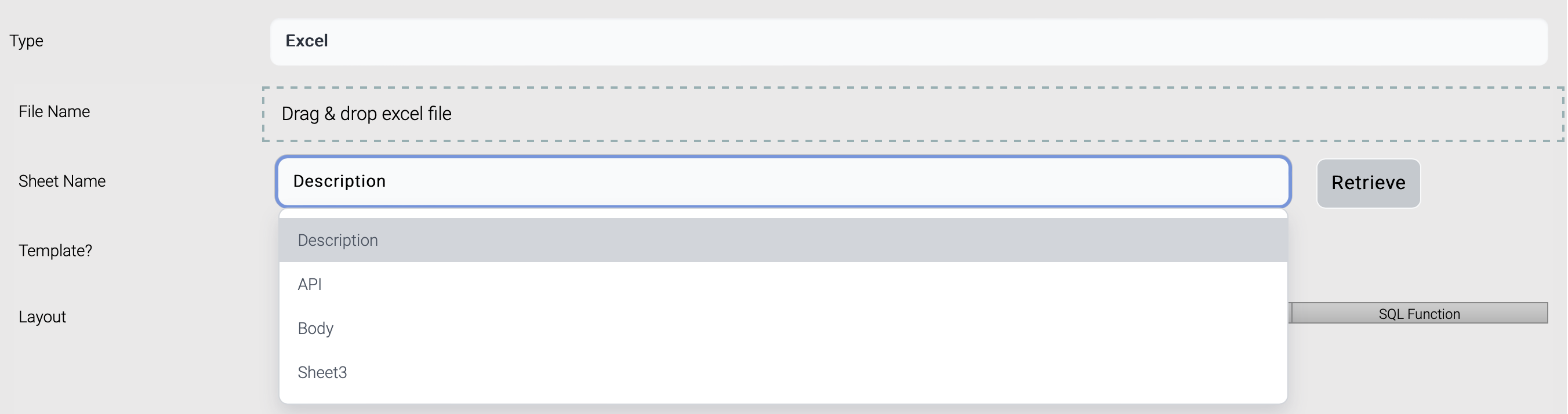

| Column Name | Column Description | Input Type | Allowed Values |
|---|---|---|---|
| FIDLE ID | Field ID to use. Automatically generated | not allowed | |
| Field Name | real field name : table column, message field | mandatory | |
| Field Description | Field description | optional | |
| Type | Field type | mandatory |
|
| Length | Field length. If length is not fixed, just enter 0 | mandatory | only number for binary type, only 4 is allowed |
| format | Field format. Used for Number and Date for Number, use NNNN.NN. The dot means a point. This point is included in the field length. for Date, use java date format | optional mandatory for date | |
| fill letter | this letter is used to fill remaining bytes, when the field is used for fixed length data For Number type default fill letter is 0. For char type default fill letter is ' ' | optional | one byte letter. |
| alignment | alignment type - left, right. For char type, left alighment is defult. For number type, right alignment is default. | optional | L - left R - right |
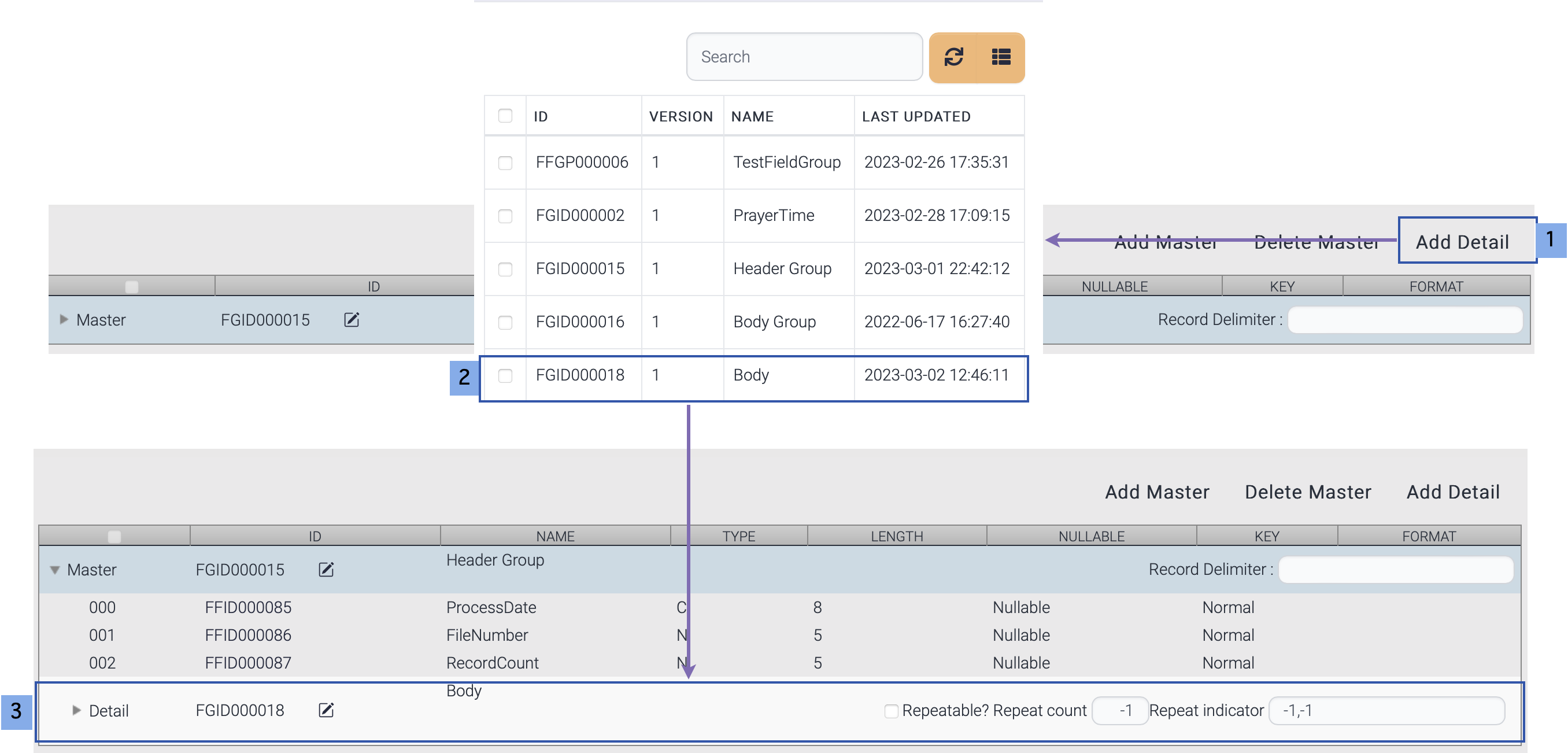
| length field type | indicates this field shows the length of partial or entire data | optional |
|
| adjustment value | Used when this field is length field which shows partial or entire length of message. If the length shows the entire length, adjustment value is 0. But when this value doesn't include all the fields in the field group or entire message, the correct length should be adjusted by this adjustment value. Add the adjustment value after calculating the length value. for example, length value is 100 and adjustment value is 8. Result length value is 108. length value is 100 and adjustment value is -8. Result length value is 92. | optional | > 0 = 0 < 0 |
| is key | it shows this field is key field or not several key fields are allowed for one field group | optional | Y = Key field N = Normal field |
| nullable | used when this field stands for table column. If the input value is null, and nullable is true, then null data is inserted into table. Default value is nullable | optional | Y = Nullable N = Not null |
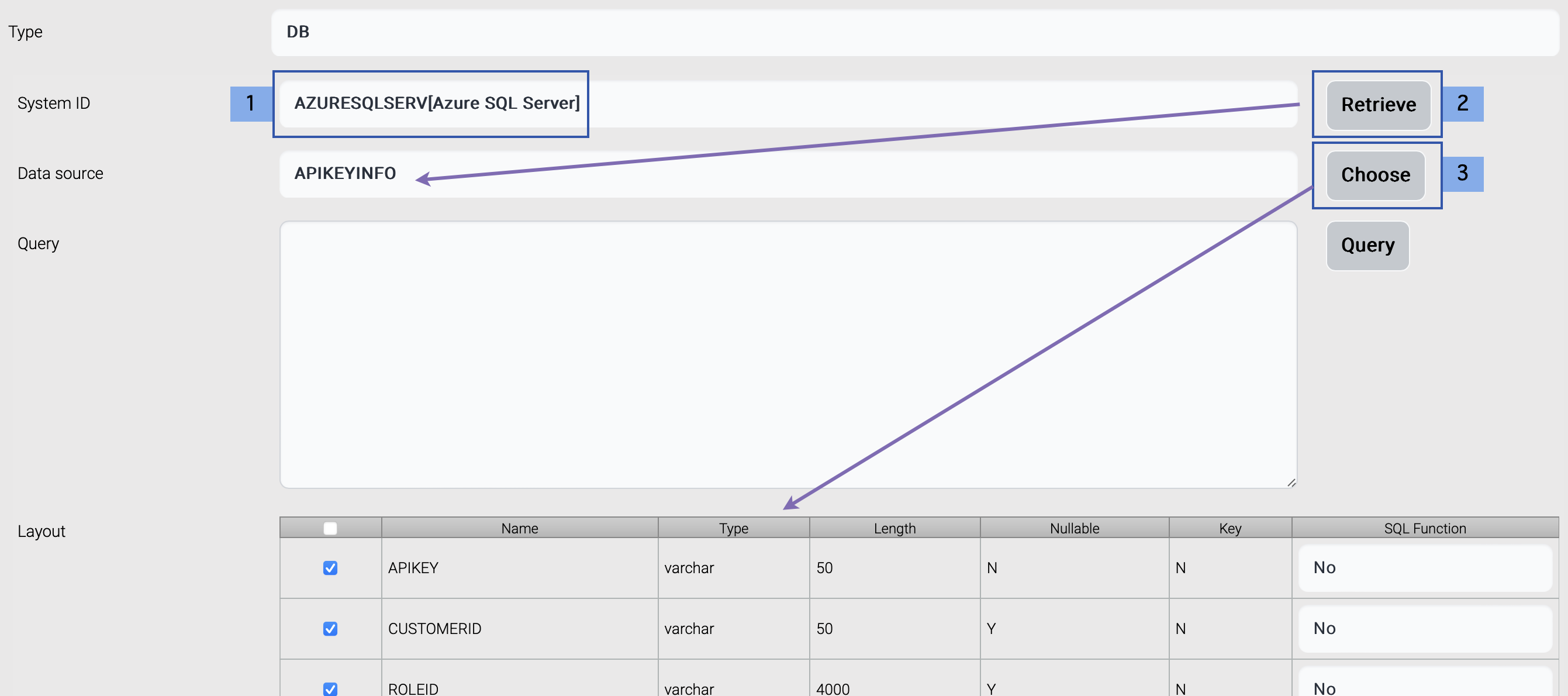
| is sql function | Used after transformation for table operation. If sql function flag is true, the result value of the transformation of this field is treated as a sql function and generated sql query contains the result as a part of the query, not the variable. | optional | Y = SQL Function N = normal field |
| inout type | for stored procedure default is input | optional | I = IN O = OUT B = INOUT |


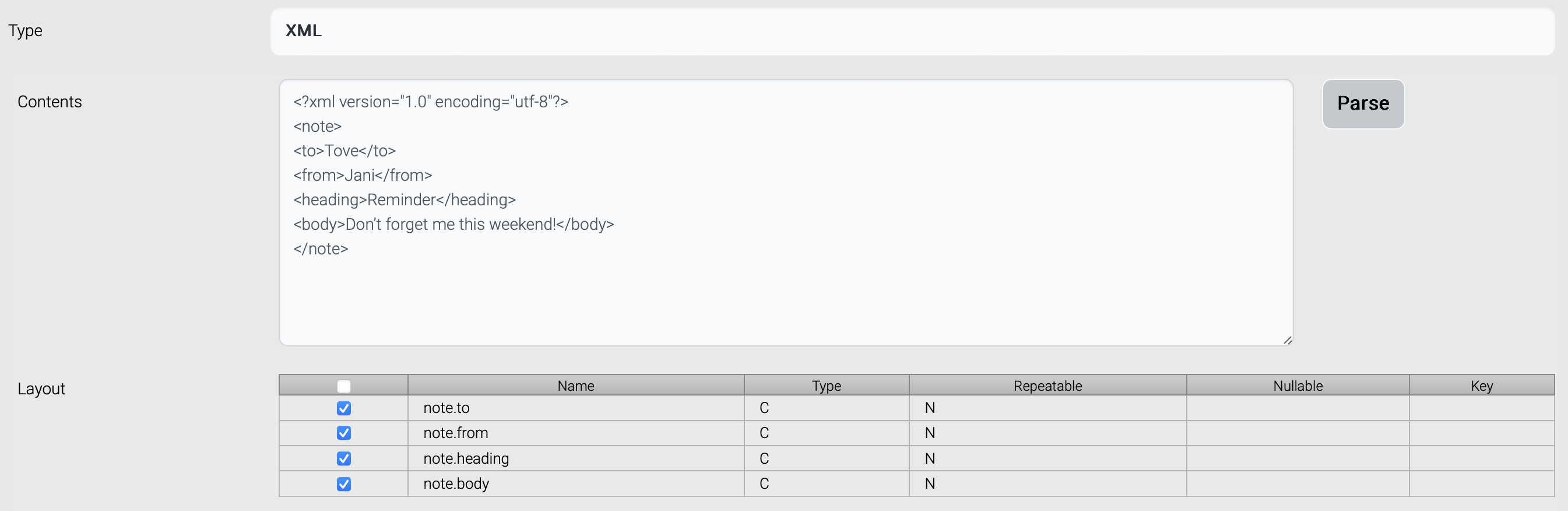
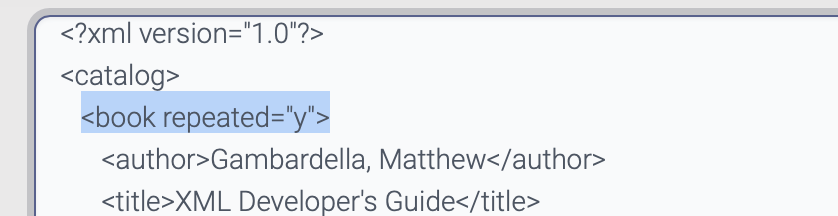
\
\
-
\
\
\
\
| | ----------------------------------------------------------------------------------------------------------------------------------------------------- | \