 ## **Input**
## **Input**
| Attribute | Description |
|---|---|
| Input Params | Input data or parameter for input data. |
| Input Fields | Input field list. This attribute is used to store part of the input data. Target fields are extracted from input data. Input data should be a list of Map or JSONObject. |
| Column Delimiter | Column delimiter. Default delimiter is comma(,). This delimiter is for output file. Hexadecimal values can be used if the delimiter is not printable character. Use 0x to set hexadecimal values. The length of hexadecimal value should be multiples of 4. ex) 0x1B or 0x1E0x1D |
| Header Included | If yes, the first line of the output file is header - column names. |
| Data Structure Id | If Header Included = No, input data are be parsed with data structure information. |
| Output Path | Output directory |
| Output File | Target file name |
| Mode | Write mode
|
| Attribute | Description |
|---|---|
| ResultPath | Output directory |
| ResultFile | Output file |
 #### Source
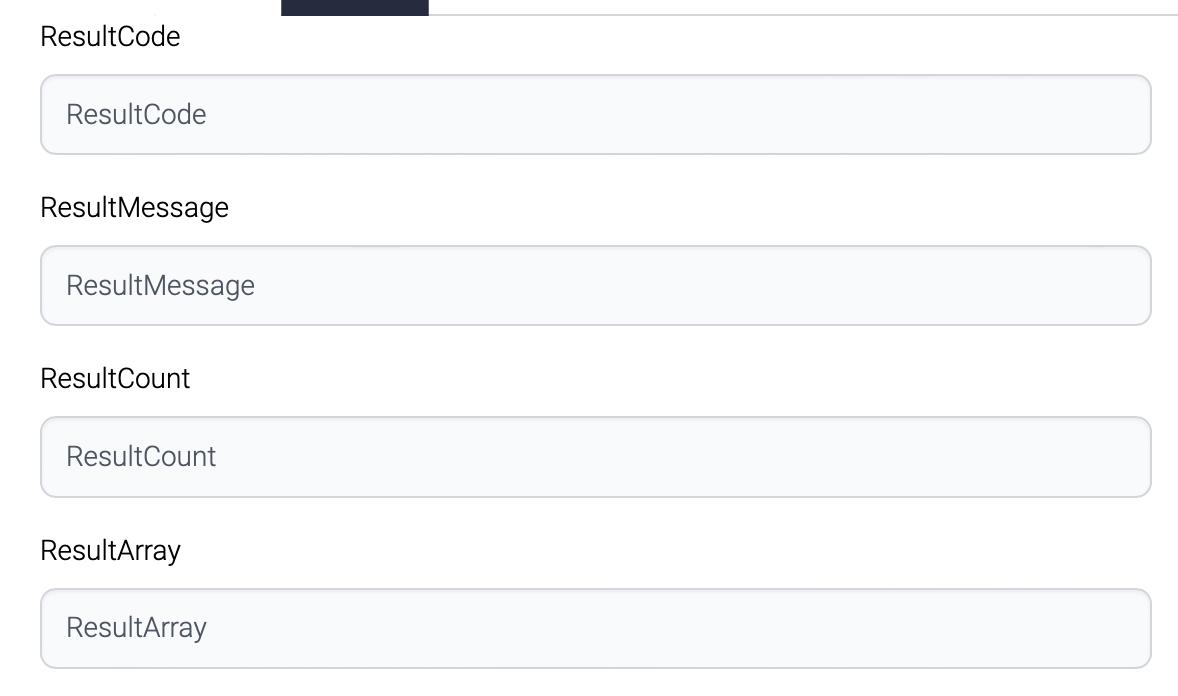
The SQLExecutor retrieves data and temporarily stores it in a local file before saving it. During this process, the record is carried by a parameter called ResultArray.
| Input | Output |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|  |  |
#### Target
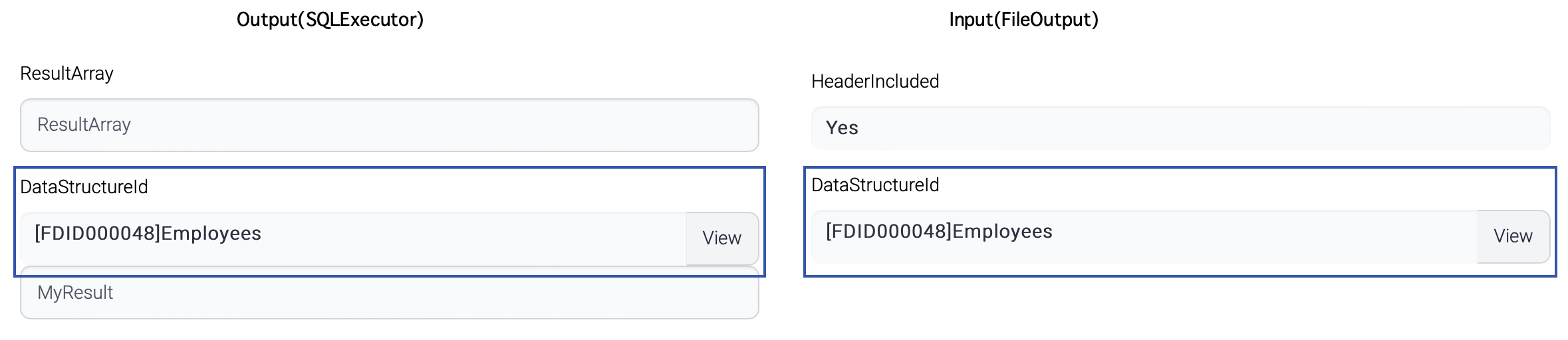
The FileOutput task uses the data from the ResultArray parameter to generate the output file. The output file includes a header row, and the column delimiter used is represented by the hexadecimal value 0x40, which is equivalent to the "@" character.
| Input | Output |
| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------ |
|  | |
### **DB To File 2**
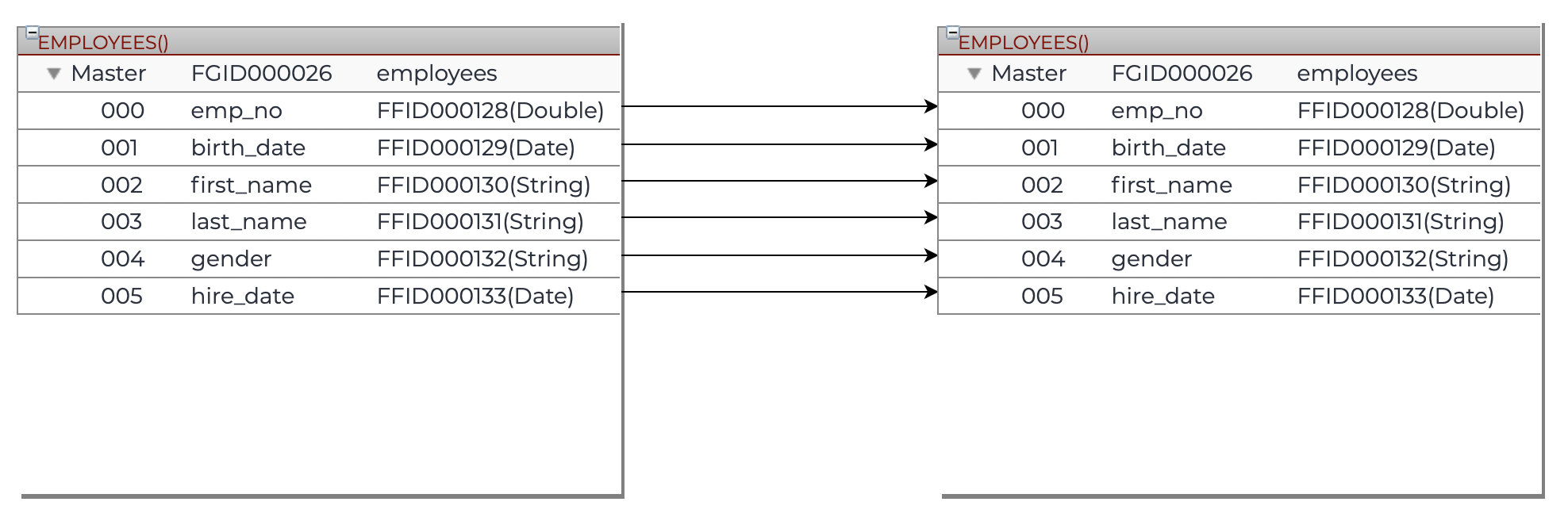
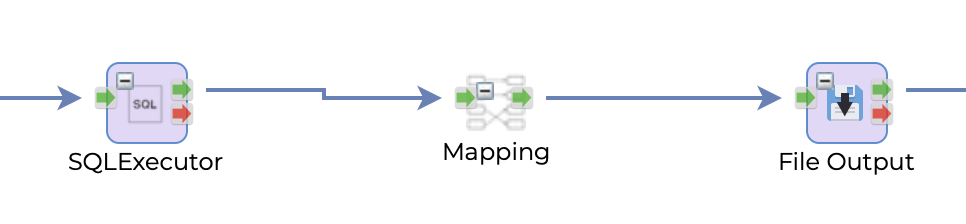
The Mapping component in this scenario refers to a task that maps or transforms data from the input source to the output destination. It can be used to modify, enrich, or decorate data with additional information before writing it to the output file. For example, it can be used to concatenate or split columns, apply calculations, or add timestamps or metadata to the data. The Mapping component can be configured with various rules and functions to transform the data as required by the business logic. Once the data is transformed by the Mapping component, it is passed on to the FileOutput task which writes it to the output file.
#### Source
The SQLExecutor retrieves data and temporarily stores it in a local file before saving it. During this process, the record is carried by a parameter called ResultArray.
| Input | Output |
| -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|  |  |
#### Target
The FileOutput task uses the data from the ResultArray parameter to generate the output file. The output file includes a header row, and the column delimiter used is represented by the hexadecimal value 0x40, which is equivalent to the "@" character.
| Input | Output |
| --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------ |
|  | |
### **DB To File 2**
The Mapping component in this scenario refers to a task that maps or transforms data from the input source to the output destination. It can be used to modify, enrich, or decorate data with additional information before writing it to the output file. For example, it can be used to concatenate or split columns, apply calculations, or add timestamps or metadata to the data. The Mapping component can be configured with various rules and functions to transform the data as required by the business logic. Once the data is transformed by the Mapping component, it is passed on to the FileOutput task which writes it to the output file.