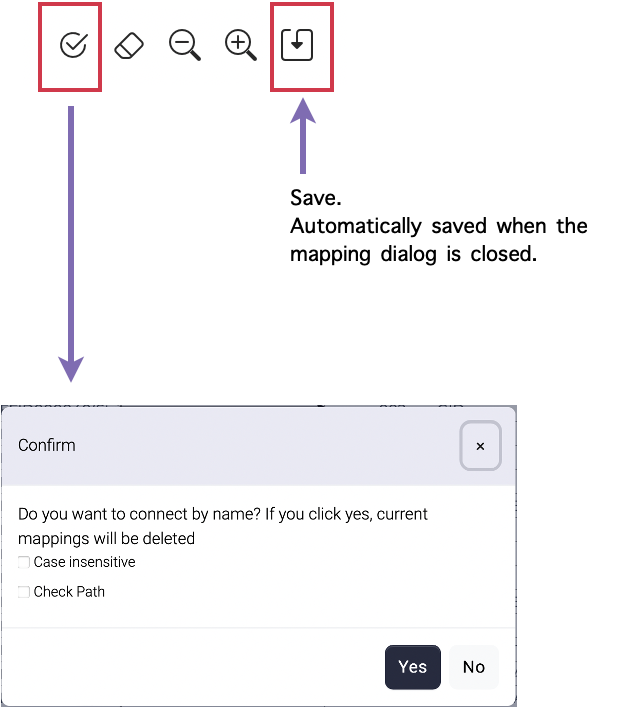
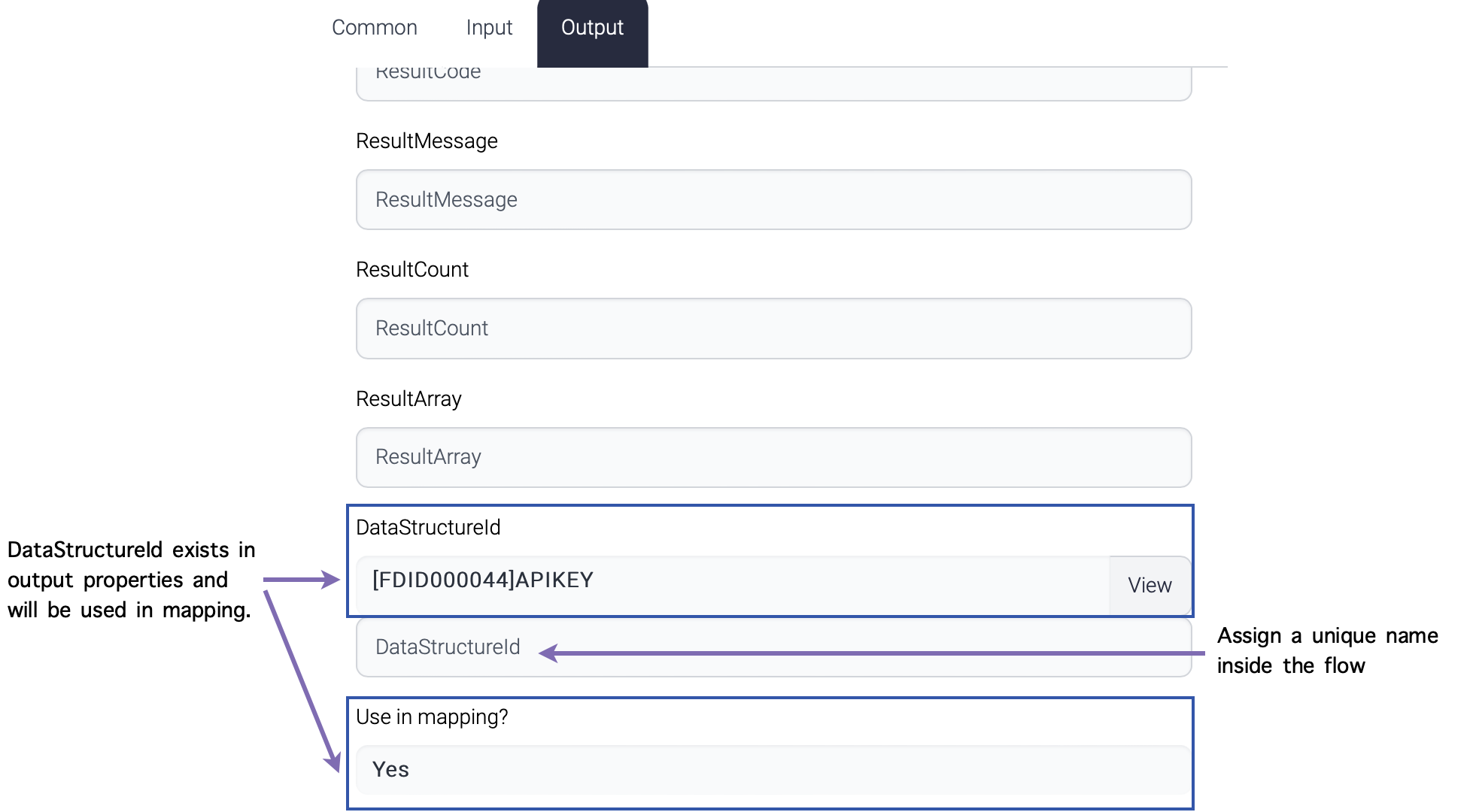
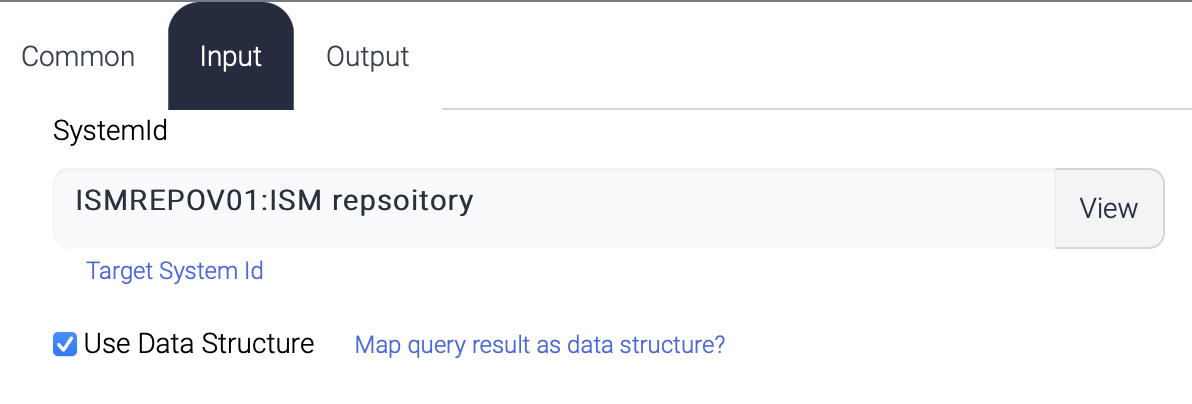

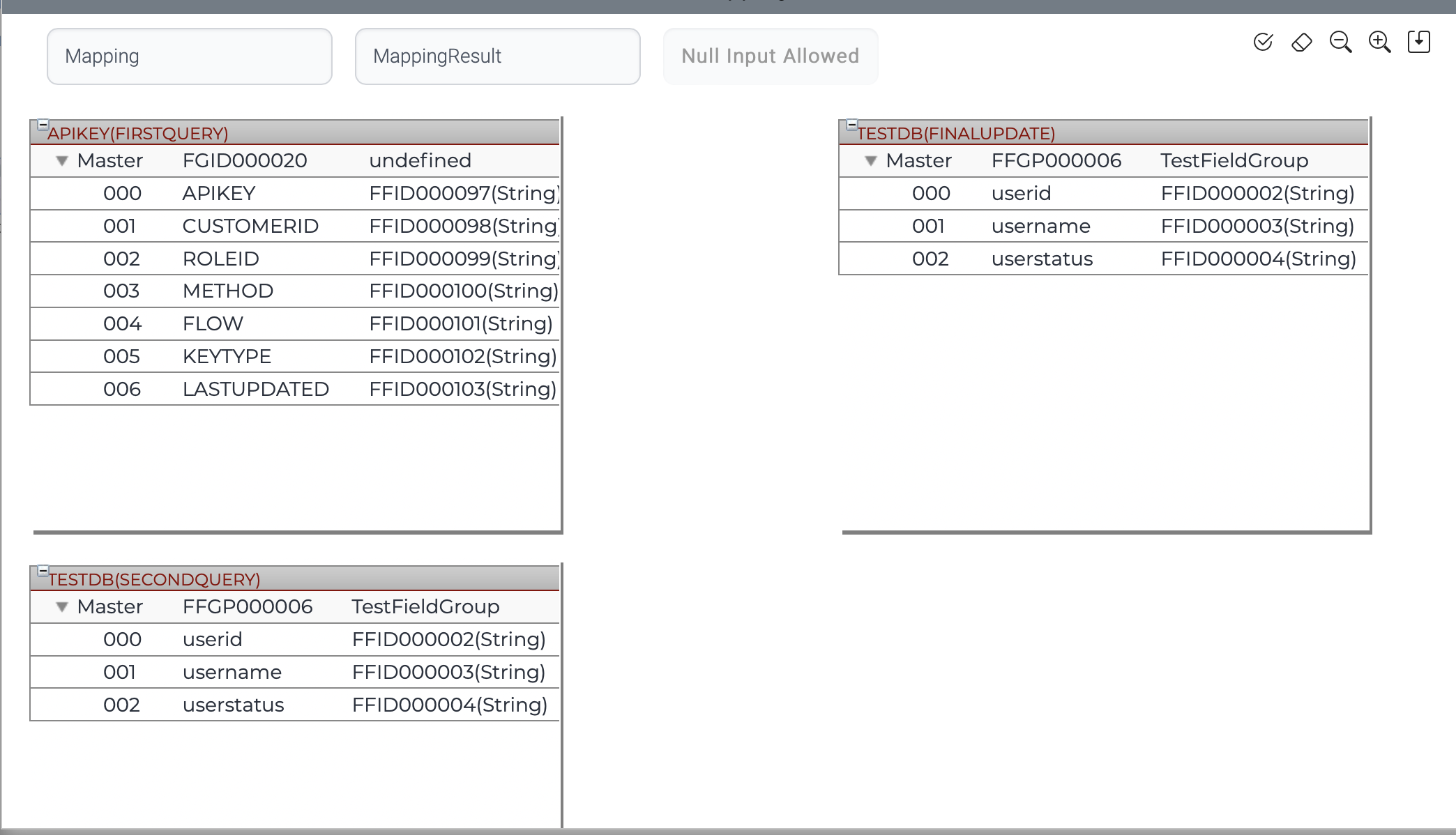




| Type | Description |
|---|---|
| Default | Default value. · Default value is set if no input value is connected. · Default value is appended if input value(s) exist. |
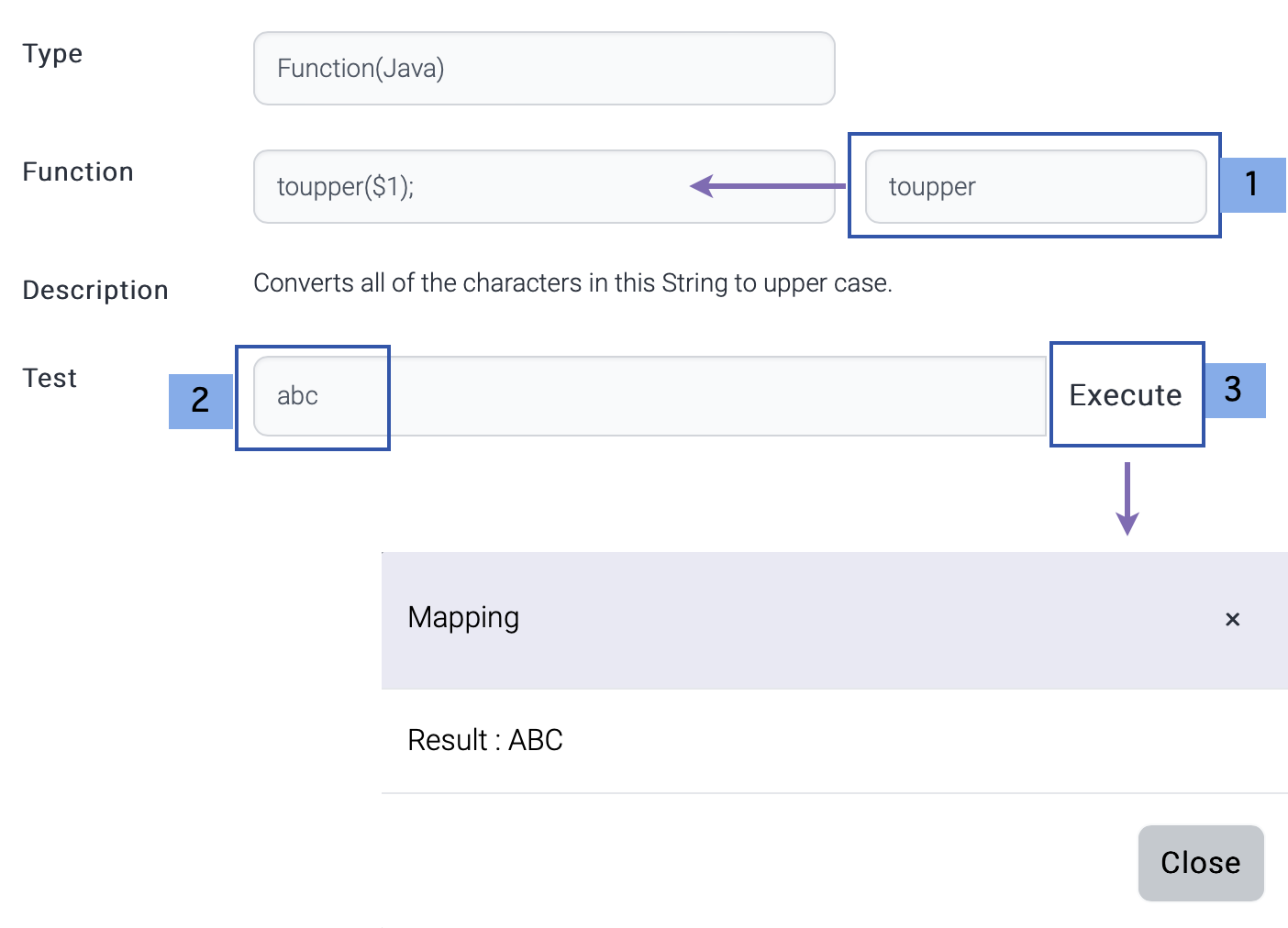
| Function(Java) | Java class to generate output value. |
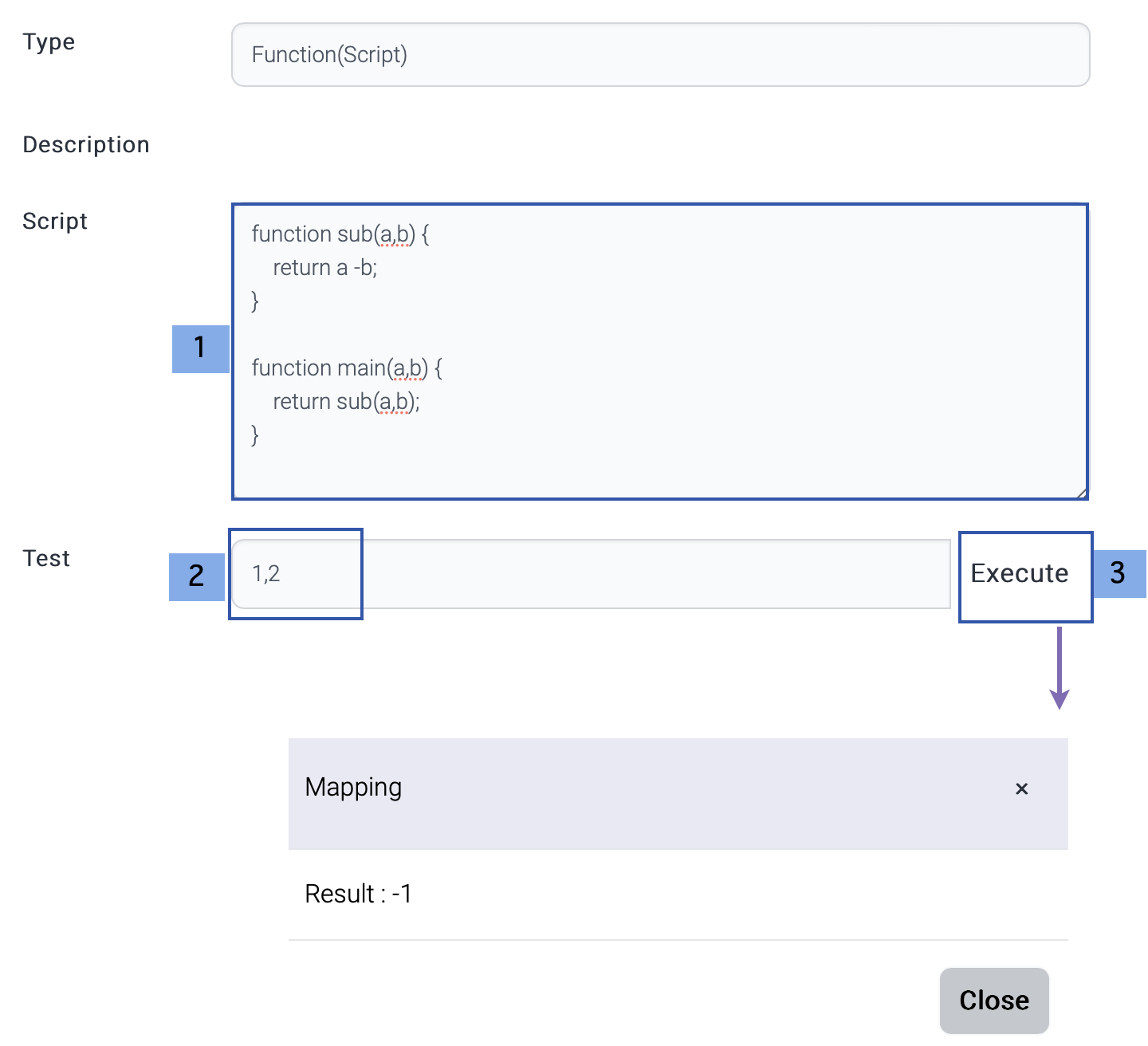
| Function(JavaScript) | JavaScript to generate output value. |